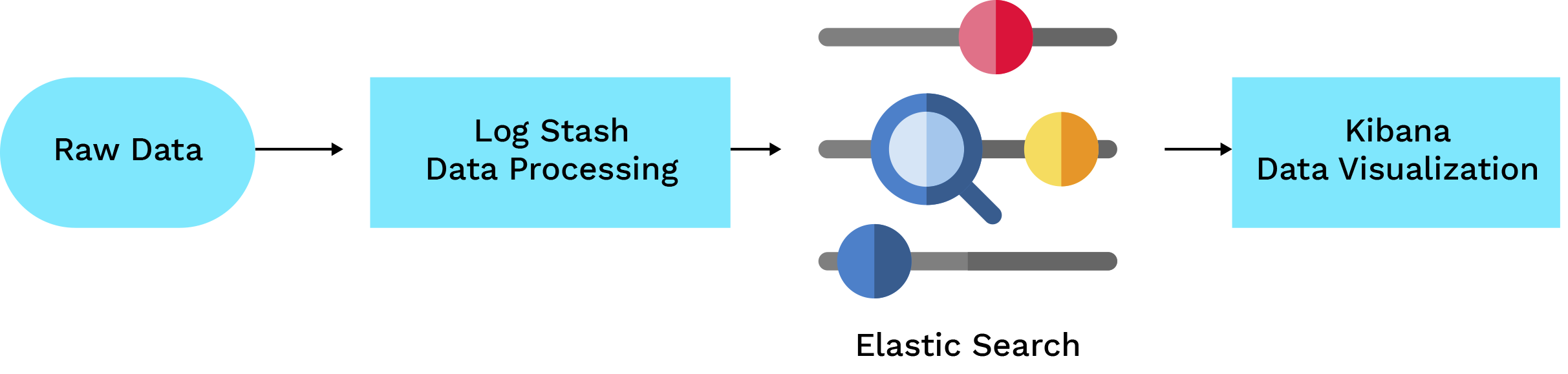
In today’s world, dealing with big data is a major challenge. We recommend adapting Elasticsearch as a solution to mitigate this problem. With Elasticsearch, you can process thousands to billions of data points in a fraction of a second. The Elasticsearch engine is extremely powerful and efficient in handling large-scale data processing tasks.
The majority of industries are facing challenges as data sizes continue to grow. To provide robust and sustainable solutions, many companies are now adapting Elasticsearch and moving away from traditional databases. Elasticsearch offers a scalable and efficient approach to handling large volumes of data, enabling organizations to overcome the limitations of conventional database systems.
What is Elastic Search?
Elastic search is a powerful engine that supports a distributed, full-text search over an HTTP protocol and works based on schema less json. major adaption reasons as below:
- Restful search API
- Analytics engine is very powerful.
- Industry data growing use cases.
Elastic search is a distributed, RESTful search and analytics engine capable of addressing a growing number of use cases. Elastic search was designed to store data centrally and offer the quickest possible data search. It was quite powerful in terms of analytics and very easy to scale it.
Why Elastic search?
- Easy to use for different kinds of telemetry or row data.
- By utilizing elastic search we can find distributed documents via built in powerful search engine.
- Majorly elastic search deal with many kinds of dataset,
- 1. Structural and semi structural.
- Textual
- Numerical
- 4. Geospatial
– Elastic search having support for several languages: Java, Ruby, Python, Perl, .Net.
Features:
- We can modify index-specific settings such as shard, paging extensibility and analyzer etc.
- In elastic search mapping is one best part work dynamically, which is designed data attribute types that attributes store in index.
- Ideally if indices grow, we should maintain time base index, if we are having index with 16-20 GB data Index, retrieval quite easy, if data grows, we should maintain separate index.
- Replication is easy.
-Major built in feature provided by elastic search such as Aggregations, pagination, quickest search filter, Fuzzy query, streaming.
Terminologies:
- Index: The index comprises documents that share common characteristics.
- Cluster: A cluster could be a single or group of servers that holds entire information’s/data.
- Sharding: Shard is smallest part of the Lucene index.
In Elasticsearch terms, Index = Database, Type = Table, Document = Row.
- Nodes: Primary /secondary
ELK : (Elastic search, Log Stash, Kibana)
Advantage/ Dis-advantage:
| Advantage |
| Scalability easy (primary and secondary node) |
| 2 billion documents indexed (16-20 Gb recommendable) |
| You can integrate with major cloud Azure, Aws, Google cloud/Amazon |
| Built in tolerance and recovery features. |
| Dis-advantage |
| Data processing can be CPU-intensive. |
| Query mechanism can be complex to grasp / Hard learning curve (Query language) |
| Complex licensing structure. |
Elastic search internal backend diagram/architecture:

Architectural diagram explanation:
A cluster was designed in such a way to handle various things, in order to tackle with loss of data from single node or within network outage or power failure loss we can adapt this. You may utilize cross-cluster replication remotely for replicate data sync.
All nodes within the cluster, will exchange request and response data, there was master and secondary nodes concept available.
Each Elastic search index consist of documents, each document was associated/distributed in the shards, so that while querying on the index through shards specific document will retrieved and optimum output will be delivered to the users.
Use Cases: Elastic search use cases tailored to particular industries:
- E-commerce :- Product Search and Recommendation: Use Elasticsearch to enable faceted navigation, tailored recommendations based on user preferences and behaviour, and product search features.
Use case: Catalog Management: Manage inventories, index and search product catalogs, and enhance product listings for search relevance by using Elasticsearch.
- Finance : – Fraud Detection: Use Elasticsearch to analyze transactional data in real-time, keep an eye out for questionable activity, and spot any fraudulent tendencies.
Use case: Compliance and Regulatory Reporting: To make compliance monitoring and reporting easier, use Elasticsearch to index and search transaction records, audit logs, and regulatory documents.
- Healthcare : – To Analyze patient records and medical imaging data and clinical history records, This will provide quickest/promptly information based on analyzer for making history base decision.
Use case: Health Data Analytics: To support research on clinical trials, and public health initiatives, use Elasticsearch to analyze healthcare data, including patient outcomes, population health trends, and disease surveillance.
4. Smart Grid Monitoring: To detect power failures, optimize energy distribution, and manage demand-response programs, use Elasticsearch to analyze data from smart meters, sensors, and Internet of Things devices.
Use case – Asset Performance Management: To improve operational efficiency and dependability, use Elasticsearch to track the performance of vital assets like pipelines and power plants, evaluate telemetry data from the equipment, and forecast repair requirements.
- Industrial laundry: Industrial laundry each wash cycle can be monitored via events, each events can be monitored and can be store into elastic search.
Use case: Commercial laundry can be monitored and telemetry can be store into elastic search.
Disaster Recovery:
DR (Disaster recovery) is critical aspect while for system IT infrastructure, In terms of elastic search a disaster could be network failure, node failure or network outage.
Disaster Recovery Plan: To make sure your disaster recovery plan functions as intended, test it on a regular basis. It will provide us feasibility plan, through which we can quick fix and provide resolution of the problems before a true catastrophe happens.
Monitor Your Cluster: Keep an eye on the health of your cluster by utilizing the Elasticsearch monitoring features. Based on real-time analysis, it will guide us early stage implementation and resolution.
Refresh Your Cluster: Update your Elasticsearch cluster often to take advantage of the newest features and enhancements, especially disaster recovery-related ones.
Protect Your Cluster: Put security measures in place to guard your cluster against intrusions that can alter your data, such as user authentication, encryption, and access control.
Back up strategy:
- Regular Snapshot
Taking regular snapshots is one of the efficient disaster recovery approach for Elasticsearch. A snapshot is a copy of an Elasticsearch cluster that is currently in operation. Snapshots of a cluster as an all or certain indices are also possible.
In order to create a snapshot, we have to first map and create repository, then only we can move for creation of the snapshot. A shared file system HDFS, Azure, Google Cloud Storage, Amazon S3, or any other blob store can serve as this repository. You can make a snapshot using the `PUT /_snapshot/my_backup} API after the repository has been registered.
To protect data loss, never forget to take snapshots on a frequent basis. Based on business needs it will be determining what frequency/occurrence we need to take snapshots.
- Replication
Data replication is supported by Elasticsearch natively. Every index in Elasticsearch is divided by default.
You can control number of replica by `index.number_of_replicas` parameter allows you to choose how many replicas there are. It is advised to have at least one copy for each shard in case of disaster recovery.
- Cross cluster replication:
Cross-cluster replication is an option for more resilient catastrophe recovery (CCR). With CCR, you can duplicate indices in a unidirectional or bidirectional manner between clusters. This is especially helpful for disaster recovery because it offers a real-time backup of your information.
In order to utilize CCR, you must first set up a remote cluster and then setup auto-follow patterns using the `PUT /_ccr/iot/my_auto_follow_pattern` API.
- Re-Indexing:
Reindexing is made easier by Elasticsearch’s specially in re-index API, which eliminates the need to create proprietary code or make use of lower-level APIs like the now-deprecated “Scroll API” or the “Bulk API.” It is noteworthy that the Reindex API internally makes use of the Bulk API and the “search_after” option (which took the place of the Scroll API) to effectively manage the reindexing operation.
Key takeaways / Conclusion:
If we are in a growing industry in terms of data, we should recommend and adapt elastic search is a good solution. There are lots of advantages if we compare with databases like mysql/MSSql/NoSQL then elastic search 3X is faster compared to other competitors.





