A robust defect detection system is the backbone of any quality control system. The advent of deep learning and advancement in computer vision technologies has changed the quality check process completely. It is important for any manufacturing industry to check that the product is in perfect condition and free from all defects before sending it to the customer. A robust check not only saves the recall time but also builds customers’ trust in the organization.
In most cases, a product can be classified as defective if it is not identical with the standard product. The defect can be a printing mistake, missing a label, missing parts, or dents on its surface. To train a deep learning-based defect detection model, it requires a dataset with various samples of each class that it is expected to detect. For example, a model that detects a dent in the tin container, is required to be fed with several images of dented containers with several types of dents in the training phase. Collecting data manually for a non-exhaustible class like ‘dents’ is not that straightforward. Hence, this problem was solved by using the digital twin technology.
Using the digital twin technology, we have effectively mimicked the industrial environment. Within a simulator we have captured the data with different angles and conditions. Several l types of defects like dents in varying sizes and shapes, label and printing errors, missing parts, etc were introduced. A YOLOv7 model was trained for defect detection on our dataset. As a Proof-of-Concept (PoC) the trained model was deployed on a toy conveyor belt of size 3.5 X 1 ft to detect defects in bottles.
In the next section we will discuss some of our data creation methods, model training and results in detail. The motive of this article is to educate developers and researchers of computer vision by sharing our experiences of training a DL model on synthetic data using simulators.
Data Creation
Training deep learning models requires an enormous, annotated dataset, one that includes all the real-world scenarios. Acquiring such a dataset can be laborious and challenging in some cases, defect detection is one of the examples. As a solution, we proposed a synthetic dataset creation pipeline by exploring the digital twin technology. Digital twins work by digitally replicating physical objects, processes, or systems. These digital replicas, often called assets, can be classified as functional or static, based on the nature of these assets.
Static digital replicas are created using real-world references of the object such as dimensions, its materialistic property, its reflective property, etc. Functional or dynamic digital twins are more complex and require data that is dynamic in nature. For example, the data coming from various sensors installed in the real object captures its movement, temperature, etc. Digital assets are useful not only in simulation but also in monitoring, analysis, and optimization.
The journey of synthetic data creation using digital twins starts with the creation of a 3D model or the asset of the object. To create an asset, we need 3D modeling tools and the real-world reference of the object. Some of the common modeling tools are: maya, unity, blender, etc. In this article, we have chosen blender for its user-friendly interface and robust functionality. Blender provides liberty to the users to introduce variations in physical properties such as lights, colors, textures, materials, and other environmental conditions. In addition to that, another feature that we used extensively was called sculpting. Sculpting was used to introduce crumples and dents in an object.

Figure 1. Blender sculpting
At first, to create a digital asset we acquired reference information about dimensions, materialistic properties, colors, and textures of the objects—water bottles of several types. Next, the mesh, which is the best fit for that object is chosen, the measurements are set, and then it is deformed using various editing features in the actual object. Once done with the shape and size, the required materialistic properties, colors, and texture were applied. We can also use or purchase existing 3D models as a base model, if available. On the base model, we applied texture, color, transparency as needed. This was followed by introducing various defects such as a missing cap, label-nonalignment, printing mistakes, ink smudging, half-filled and empty bottles, etc. We also used sculpting to create crumples in the bottles.

Figure 2. Digital twins of different cases of defective and non-defective bottles
When the asset creation is completed, they are exported into simulators. It is important to bake the object for smooth transfer from blender to any other simulator without breakdown. By baking textures, our objective is to consolidate the materials within a single object. The baked objects are then exported into .fbx (FilmBoX) or .usd (Universal Scene Description) file format. To create an annotated training dataset out of these few digitally created objects we used NVIDIA’s ISAAC simulator.

Figure 3. Overview of creating digital assets
ISAAC SIM is a powerful simulation platform developed by NVIDIA for training and testing autonomous robots and other AI-driven systems. It enables us to create photorealistic, scalable, and physically accurate virtual environments for developing high-fidelity simulations. Inside the simulator, the user can create the desired virtual environment and place the objects imported in a usd file. The user can also leverage upon the domain randomization feature provided by the simulator to introduce variations in lighting conditions, occlusion, pose and other environmental factors to create a more robust dataset.
To automate the domain-randomization feature, a Script Writer is provided where one can write python script to automatically set and tune coordinates of objects, cameras, and other parameters for domain randomization. Once the object is set at given values, the replicator can capture the image in the RGB format and can store other parameters in a textual format. This textual information can be utilized as an annotation file. To create a bottle-defect-detection dataset, imported 3D models were created using the blender within the simulator and placed on a moving conveyor belt.

Figure 4. Imported file in Isaac SIM
We wrote a script to capture the images and the respective annotation file in large numbers with different poses and lighting. The annotation file contains the class name, bounding box information for each class present in the respective RGB file. This dataset is then used for object detection model training.
Model Selection
We selected a state-of-the-art object detection model YOLOv7 to train our defect detection model. The YOLO model architecture consists of a backbone network, a neck architecture, and a detection head. The input image frames are converted into embeddings (image features) through a backbone network. The neck architecture combines and mixes these features neck, and then they are passed to the detection head. The detection head block predicts class probabilities, bounding boxes, and confidence scores for each object in the input frame. The basic architecture is shown in figure 5.
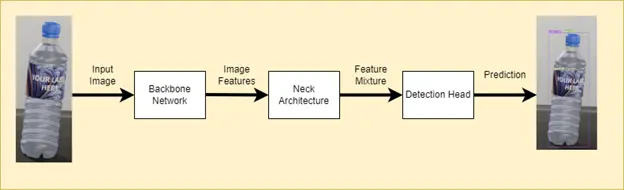
Figure 5. General YOLO architecture.
The YOLOv7 model, part of the YOLO family, is specifically designed for real-time frame processing with high accuracy. It incorporates refined modules and advanced techniques to enhance object detection accuracy. YOLOv7 leverages the Extended Efficient Layer Aggregation Network (ELAN), which focuses on efficiently designing networks by balancing the shortest and longest gradient paths. This approach ensures that the deeper networks converge and learn more effectively. Additionally, YOLOv7 utilizes model scaling to adjust model attributes, enabling the creation of models at different scales to accommodate various inference speed requirements. The model also includes new trainable parameters which have helped YOLOv7 achieve a state-of-the-art performance in object detection tasks.
Defect Detection Pipeline
Figure 6 shows a high-level diagram of a mineral water bottle defect detection pipeline. It consists of training and adding inference to the pipeline. The training pipeline consists of data collection, data annotation and model training phases. We start by acquiring diverse images of mineral water bottle images, both with and without defects. For the bottle defect detection task, the dataset consists of annotated images of 640 x 640 resolution, pre-split into training (800), validation (200) and test sets (80). The label annotations for defect detection task have 5 classes (such as cap, crumbled, label, no-cap, and bottle.) Each image is accurately annotated to indicate the presence and location of different defects. The YOLOv7 annotation for each image is in the form of a text file in which each line specifies a single object. The line describes the class, the x center co-ordinate, the y center co-ordinate, the width, and the height of the bounding box of that object. The bounding box coordinates are normalized to the image dimensions (i.e., their values between 0 and 1) and the class values are zero based numbering (i.e., numbering starts with 0). Using the labeled dataset, we have trained the YOLOv7 model for 200 epochs to recognize defects on mineral water bottles. By leveraging transfer learning and fine-tuning techniques, we ensure that the model learns to detect different defect types and bottle variations. The model’s performance is evaluated on metrics such as mean average precision (mAP), recall and precision. We fine-tune the model to achieve optimal accuracy and efficiency.
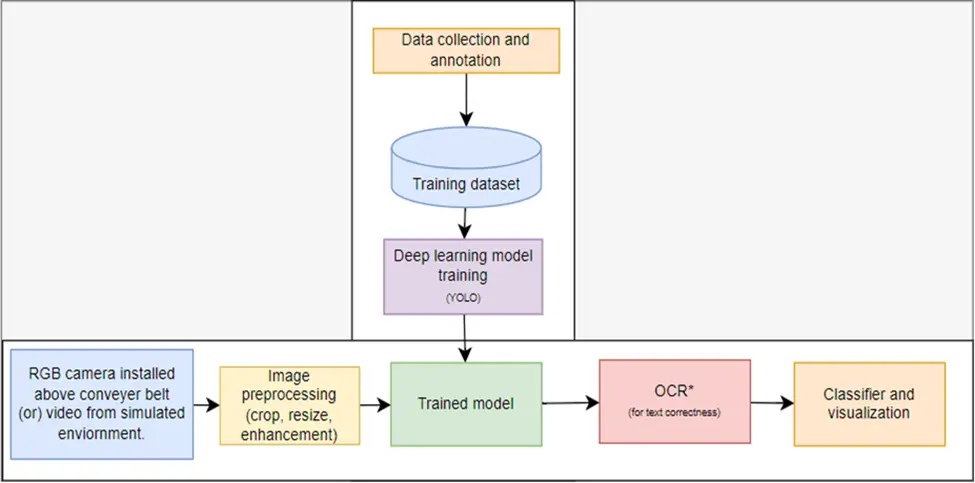
Figure 6. Defect Detection Pipeline.
The inference pipeline consists of the input video acquired using an RGB camera installed on the conveyor belt or in a simulated environment, a pre-processing block, a trained model, and a post processing block. With a trained model, we deployed it for inference on new images (synthetic/real world images). The model processes the frame in real-time by detecting defects and drawing bounding boxes around them. It also classifies the bottles as defective if it detects anyone of the labels from no-cap, crumbled and no-label. If the label is present, it then checks for defects such as label misprint, rolled tape, inverted label and partial printing using OCR and other image processing techniques. If none of these defects are present, it classifies the bottle as non-defective. We integrate the defect detection system seamlessly into the production line, automating the quality control processes.
Results and Conclusion
Figure 7 shows the inference results on a single frame of synthetic video data generated using ISAAC Sim. The bottles are placed on a moving conveyor belt. The model performs inference on each image, the output consists of bounding boxes with labels such as bottle, cap and label and its corresponding confidence score as shown in figure 7 (b). In figure 7 (c), the bottles with no-cap, no-label and partial label are labelled defective (red bounding box) while bottles with cap and good label are non-defective (green bounding box). Similarly, figure 8 shows the classification result on the real-world data.

Figure 7. Inference results on synthetic data. (a) Input Image, (b) Model output and (c) Defective/non-defective classification.

Figure 8. Inference results on real world data. (a) Input Image, (b) Model output and (c) Defective/non-defective classification.
In this blog, we have explored how a defect detection model can be easily trained using a digital twin and a simulator. We have also trained a YOLOv7 detector in a bottle defect detection use case as a proof-of-concept. The model trained on the dataset achieved 94 percent accuracy. This will be further enhanced by deploying the same pipeline on EIC-AMR equipped with manipulation arms.








