Introduction
Today, in the multi-core processor world, when there is cache data transfer we usually come across issues with the regularity and consistency of the data. This data transfer should be done following protocols (cache coherency) specially where Direct Memory Access (DMA) is involved to avoid incorrect functionality of the application. Here in this blog, we will learn about the risk with caches and how to avoid it with the help of cache coherency with examples. We will also get a glimpse of a real time example of a problem from how to identify cache coherence problem to fixing the problem.
So, to learn about cache coherence let’s first understand the need of cache after all. Cache has the advantage of locality of memory access that stores frequently used temporary data copies from the main memory. Or in simpler words Cache is placed close to the CPU which can be accessed without any stalls thus reduces the average time for accessing memory. So, to cope with the performance gap and obtain synchronization between fast CPUs and memory speed, fast memory Cache memory is used.
Now, let’s understand some basic terms which we will bring to understanding cache coherence.
Cache Coherency
If multiple peripherals/devices are using the same memory, it will also arise the chance multiple data copies can exist for each device in cache. In short, if a cache memory is shared and modified, it will cause cache coherence problem. To ensure that older copy of the data does not get accessed, cache coherency is maintained.
Lower-level memory
Lower-level memory is a memory further from the CPU.
Higher-level memory
Higher-level memory is a memory closer to the CPU.
Read
A cache read is an operation in which a processor or a core tries to read a memory location from its cache.
Write
A cache write is an operation in which a processor or a core writes data to a memory location in its cache.
line
A cache line is the smallest unit of data that a cache operates on.
dirty
A dirty line a cache line which is valid and contains updated data that is not been sent to the next lower-level memory.
invalidate
Invalidate is the process of marking valid as invalid cache lines in a cache memory.
Writeback
Writeback refers to the process of transferring updated data from a cache line that is both valid and dirty to a lower-level memory hierarchy.
Writethrough
In a write-through approach, the cache always ensures that any updated data is immediately passed on to the lower-level memory, meaning that the cache never holds onto updated data without transmitting it to the lower-level memory.
Hit
A cache hit happens when the data for a requested memory location is present in the cache.
Miss
A cache miss happens when the data for a requested memory location is not present in the cache.
Snooping
Snooping refers to a cache operation initiated by a lower-level memory to check whether the requested address is currently cached (valid) in the higher-level memory.
principle of locality
The principle of temporal locality suggests that if a memory location is accessed, there’s a high likelihood that the same or a neighboring location will be accessed again in the near future.
Main type of Coherence Protocols
- Directory Based Protocol
- Snoopy Protocol
Directory Based Protocol
Directory-based cache coherence protocols are a type of cache coherence mechanism that maintains a centralized directory that tracks which cache or caches have a copy of each memory block.
Since the centralized directory is being used it can become a bottleneck for communication between caches. So, directory-based protocols may not be as scalable as snooping-based protocols in very large systems with many caches.
Snoopy Protocol
Snoopy Protocol uses invalid and writeback cache lines to maintain coherence. When there comes a situation where it becomes programmer’s responsibility to maintain cache coherence, snooping mechanism proven to be more efficient since it eliminates cache miss overhead caused by invalidates. When one processor updates a piece of shared data in its cache, the other processors need to be notified so they can update their own copies of the data to maintain coherence. When CPU writeback cache lines, it sends a message to all other devices to invalidate their copies of those cache lines.
In this blog, we will discuss Snoopy Protocol and its application in the case of internal and external memory data transfers using DMA. Here, below are some examples explaining how the use of Snoopy Protocol in different cases to maintain cache coherence.
- Snoopy Protocol Coherence for Internal Memory and Cache
- Snoopy Protocol Coherence Between External Memory and Cache
1. Snoopy Protocol Coherence for Internal Memory and Cache
Let’s take a simple case of DMA transfer, data is read in from one device/peripheral, processed, and written to another device/peripheral. While the CPU is processing data from one pair of Input and Output buffers, the devices/peripherals are writing/reading data using the other pair of Input and Output buffers such that the DMA data transfer may occur in parallel with CPU processing.
The DMA transfer happens when a CPU reads a cached memory location using DMA (a read has occurred), the data is directly forwarded from Cache to the CPU’s DMA controller without being updated in Memory. When a peripheral writes to a cached memory location using DMA (a write has occurred), the data is forwarded to Cache and is updated in Memory to ensure consistency between the cache and memory. Same is illustrated in the below diagram.
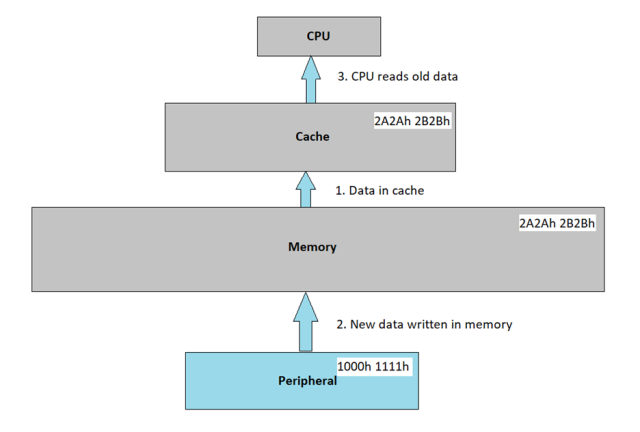
Diagram to illustrate Cache-Coherency Problem
Let’s consider that InputBuffer1 has been written by peripheral.
- Then InputBuffer2 is being written by device/peripheral while the CPU is processing data in InputBuffer1. The lines of InputBuffer1 are allocated in internal memory. Data is processed by the CPU and is written through the write buffer to OutputBuffer1.
- Now the peripheral is filling InputBuffer1 with new data, the second device/peripheral is reading from OutputBuffer1 via DMA, and the CPU is processing InputBuffer2. For InputBuffer1, the RAM cache controller copies data to input memory using snoopy protocol as mentioned in its description. For OutputBuffer1, since it is input memory and not cached RAM memory, no snoopy protocol is required.
- Buffers are then switched again, and this process goes on.
2. Snoopy Protocol Coherence Between External Memory and Cache
Here also the CPU not just reads in data from a device/peripheral and writes it to another peripheral/device via DMA, but also the data is additionally passed through cached RAM. Assume that transfers already have occurred, that both InputBuffer and OutputBuffer are cached in cached RAM, and that InputBuffer is cached in Internal Memory.
- Now when CPU has completed processing InputBuffer2, filled OutputBuffer2, and is about to start processing InputBuffer1. The transfers that bring in new data into InputBuffer2 and commit the data in OutputBuffer2 to the peripheral are also about to begin. To maintain coherence, all the lines in Internal Memory and cached RAM that map to the external memory input buffer must be invalidated before the DMA transfer starts. This way the CPU will reallocate these lines from external memory next time the input buffer is read.
- Similarly, before OutputBuffer2 is transferred to the peripheral, the data first must be written back from Internal memory and cached RAM to external memory. This is done by issuing a writeback operation. Again, this is necessary since the CPU writes data only to the cached copies of the memory locations of OutputBuffer2 that still may reside in cache RAM. Below diagram is illustrating same.
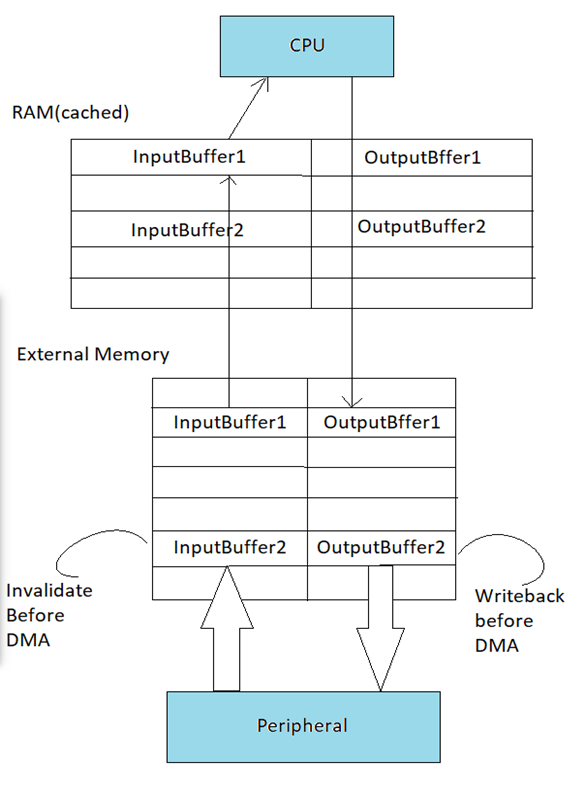
Understanding Cache Coherency with EMAC example
Let us take the example of the Ethernet Media Access Controller (EMAC) which is integrated into the network interface controller (NIC). It is a hardware component implementing the data link layer of the OSI model. It is responsible for transmitting and receiving Ethernet frames, performing tasks such as error detection, flow control, and media access control (MAC) addressing. It uses buffer descriptors to manage the transfer of data between the network interface and the host processor(device).
Buffer descriptors are data structures that describe the location, size, and status of data buffers used for network communication.
So, many times DMA engine is used to transfer data directly between the EMAC and the memory without requiring intervention from the host processor. When the EMAC receives a packet, it reads the packet data into a buffer and updates the buffer descriptor to indicate the size and status of the received packet. The receiver DMA engine can then read the buffer descriptor to determine the location and size of the received packet and process it accordingly.
- The PHY receives the packet from the network and sends it to the EMAC.
- The EMAC reads the packet from the PHY and stores it in a receive buffer in the EMAC’s internal memory.
- The EMAC updates a receive buffer descriptor to indicate the size and status of the received packet, including the location of the receive buffer in the EMAC’s memory.
- The receiver DMA engine reads the receiver buffer descriptor and transfers the received packet data from the receiver buffer in the EMAC’s memory to a buffer in the system memory.
- Once the receiver DMA engine has transferred the entire packet to the system memory, it signals the host processor that a packet is ready to be processed.
- The host processor reads the packet from the system memory buffer and processes it as required.
- The host processor then signals the receiver DMA engine to release the buffer descriptor and associated receive buffer in the EMAC’s memory for reuse in future packet reception.
Similarly, when the transfer DMA engine wants to transmit a packet between the device internal or external memory and the transmit FIFO, it creates a buffer containing the packet data and sets up a buffer descriptor of the transmit FIFO to describe the location and size of the buffer. The EMAC then reads the buffer descriptor and uses the information to transmit the packet onto the network.
- The host processor creates a packet buffer in the system memory and initializes a transmit buffer descriptor to describe the buffer’s location and size.
- The DMA engine reads the transmit buffer descriptor and begins to transfer the packet data from the system memory to the transmit FIFO of the EMAC.
- As the DMA engine transfers the packet data to the transmit FIFO, the EMAC updates the transmit buffer descriptor’s status to indicate the progress of the transfer.
- Once the entire packet has been transferred to the transmit FIFO, the EMAC issues a transmit request to the PHY (Physical Layer) to begin sending the packet onto the network.
- The PHY sends the packet onto the network and notifies the EMAC once the transmission is complete.
- The EMAC updates the transmit buffer descriptor’s status to indicate the completion of the transmission, and the DMA engine can reuse the transmit buffer descriptor to initiate a new transmission.
Now in multicore processor scenario if the shared cache memory is used to store the EMAC data such as buffer descriptors. There is chance that host processor may read the descriptor before the DMA write hit the memory Host processor could read the old stale data. So, it will stop the receive buffer descriptor to indicate the size and status of the received packet, including the location of the receive buffer in the EMAC’s memory. Here when EMAC addresses are descriptors in cacheable memory space, it is important to ensure that the descriptor is written back and invalidated prior to updating the next receiver buffer as mentioned in above snoopy protocol examples.
Conclusion
This blog covers the topics from understanding cache to finding solution of cache coherence problem with the considerations and steps involved. The above-mentioned examples might help in solving a problem related to cache coherence especially when dealing with read and write from a cache memory location. There can be a situation that even after updating a memory location reading from that memory location will always give stale data which is incorrect because programmer might have overlooked the handling of cache memory involved.
References
Multicore Programming Guide (Rev. B)
KeyStone Architecture Enhanced Direct Memory Access (EDMA3) Controller (Rev. B) (ti.com)
TCI6486CSL: TMS320TCI6486 DSP EMAC Rx DMA SOF Overrun Problem – Processors forum – Processors – TI E2E support forums






