Introduction:
The traditional industrial robot arm, a cornerstone of factories and assembly lines, stands as a testament to unwavering precision and reliability, its fixed base ensuring stability in high-speed manufacturing. But the world of robotics is constantly evolving, with an emerging breed of robots: the mobile manipulator. This innovative concept combines the power of a manipulator arm with the mobility of an Autonomous Mobile Robot (AMR), creating a versatile and dynamic machine capable of tackling a wider range of tasks.
This blog delves into the exciting potential of mobile manipulators by exploring a captivating use case: an AMR equipped with a manipulator arm designed to autonomously retrieve a colored golf ball and place it inside a mug. A voice command guides which color golf ball to pick.
This integrated solution unlocks its potential through multilingual speech-to-text conversion, empowering autonomous navigation, object manipulation, and task execution with remarkable precision and efficiency. Imagine simply speaking a natural language command in your native tongue – our system seamlessly translates and interprets the words into actionable instructions. A step-by-step journey, captured in the flow-diagram, showcases how different parts of our system work together flawlessly, including the crucial role of voice command recognition in activating the desired task.
Flow-diagram:
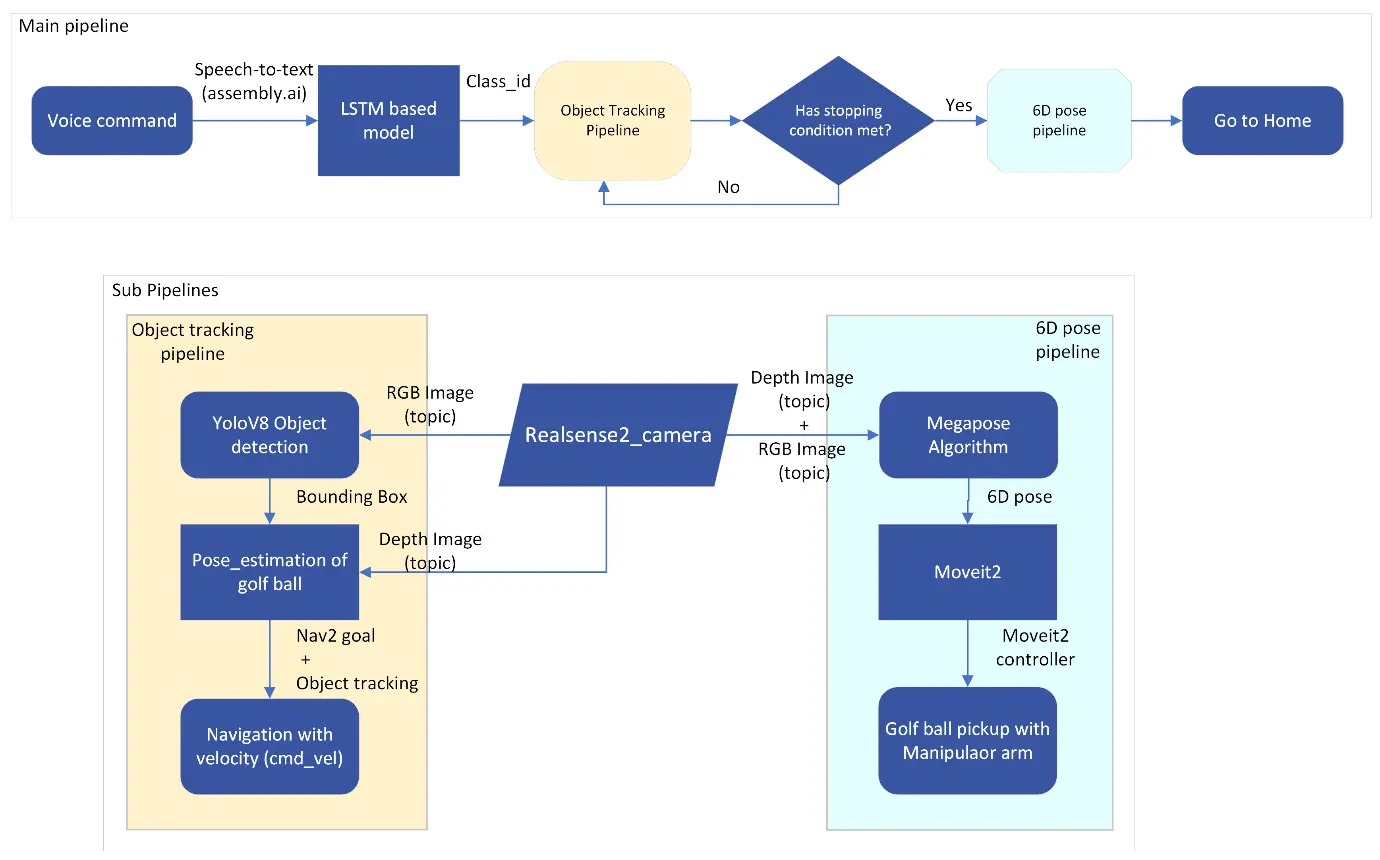
Flow-diagram of entire pipeline
Instructing the robot is as easy as speaking a natural language command. Speak out your instruction – “Pick up the red golf ball” – into a microphone connected directly to the main board of the AMR, or even remotely through Secure Shell (SSH) to a system running Robot Operating System (ROS2) [1]. Behind the scenes, a powerful speech-to-text API acts as a bridge, transforming your voice into a digital format that the computer can understand. This isn’t simple keyword matching. A sophisticated Long Short-Term Memory (LSTM) [2] network steps in. Imagine it as a highly trained language expert. Having been exposed to a vast amount of voice data and corresponding actions, it can decipher the nuances of your speech, accurately identifying the color of the golf ball that should be picked up. This entire voice recognition and intent understanding process can be handled locally on the main board or offloaded to a remote server for more complex tasks, ensuring a flexible and scalable solution.
Once it gets the color of the ball, the AMR’s next challenge is to locate the ball in its environment. This is where YOLO [3] (You Only Look Once), a cutting-edge object detection algorithm, analyzes the camera feed from the robot, acting like a keen observer identifying objects within the scene. In this case, YOLO focuses on detecting the ball, drawing a bounding box around it to indicate its location within the camera frame.
To pick the golf ball, the AMR needs to identify the ball’s position relative to its own. The bounding box gives location relative to the camera. To get the relative location, a pinhole camera model is used. The camera coordinates are converted to map coordinates using pinhole camera model and depth image information. ROS2 (galactic) Navigation stack [4] takes that location as a goal position for the AMR. Building upon the information provided by YOLO (the ball’s location) and pinhole model (the ball’s location on the map), Nav2 calculates an optimal path for the robot to reach the ball efficiently. This method is especially beneficial when navigating through obstacles or in situations where a direct line of sight to the ball might be obstructed.
To ensure seamless object tracking, the AMR first approaches the golf ball within a specific proximity threshold. Once close enough, the object tracking algorithm takes control, generating velocity commands that supersede those from the navigation (Nav2) algorithm. This precise control allows the AMR to continuously monitor and adjust, maintaining optimal positioning relative to the target golf ball. As predefined stopping conditions are met, signalling the attainment of the desired spatial configuration, the system initiates the activation of a sophisticated 6D pose estimation algorithm, MegaPose [5]. Using the location data from YOLO and depth information from the camera, MegaPose estimates the ball’s exact 3D position and orientation in space with respect to the camera. This includes not just where the ball is, but also its precise tilt and rotation. This critical information is then translated into a format that MoveIt2 [6], a motion planning framework, can comprehend. MoveIt2 meticulously plans the robot arm’s trajectory, ensuring it reaches out, grasps the ball securely, and avoids any collisions with surrounding objects.
After retrieving the golf ball, the AMR seamlessly transitions to locating a suitable mug for its placement. It employs a similar object detection strategy, searching the environment by rotating counterclockwise at its place until a mug is identified. Once detected, the mug’s location is converted into a navigation goal for the AMR using ROS2. This precise positioning allows the AMR to reach the mug and carefully place the ball inside.
The upcoming sections offer a comprehensive explanation of the algorithms and components represented in the flowchart.
Speech-to-text:
Speech recognition technology converts spoken words into written text. The process starts with capturing the voice of the user through a microphone. The analog signal is then converted into a digital format using an A to D (analog to digital) converter. Key features are extracted from the digital data to identify the most likely sequence of phonemes, the basic units of sound that make up words.
An acoustic model analyzes these features to guess the phonemes, while a language model considers grammar, vocabulary, and word probabilities to determine the most likely combination of words that corresponds to the captured audio. Finally, a decoding algorithm picks the most probable word sequence and refines it for any errors, resulting in the final text output.
In our case, the user can give commands like, “Please pick a red ball.” or “I can see a blue and a red ball, please pick the blue golf ball.”
Supply Chain Optimisation With Robotic Process Automation
LSTM based model:
LSTM stands for Long Short-Term Memory network. It is a type of Recurrent Neural Network (RNN) specifically developed to tackle a challenge encountered by traditional RNNs that is the vanishing gradient problem. Unlike traditional recurrent neural networks, LSTMs can handle the complexities of language, especially long-distance word relationships that convey crucial meaning. 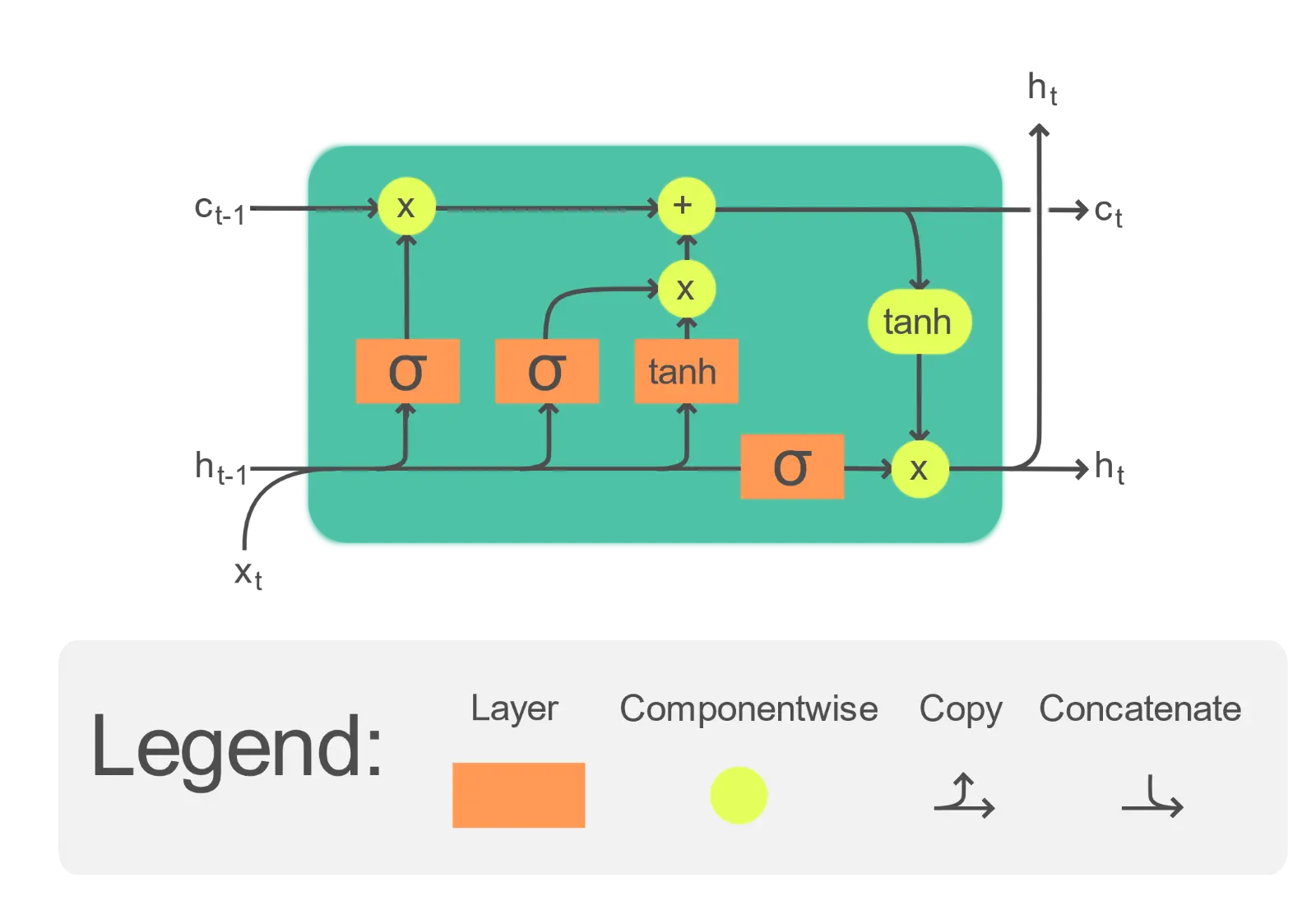
LSTM model pipeline
These networks operate like a sophisticated memory system. The text data is fed in one step at a time, and the LSTM considers not just the current word, but also information stored from previous words and a hidden state reflecting the overall context. This allows the LSTM to identify patterns and relationships within the sequence, making them ideal for information extraction tasks.
In our case, even if the user mentions multiple colors (“Pick up the red or the blue ball.”), the LSTM can understand the context. As we trained the model to identify the color of the ball, it processes the input provided and returns the corresponding color name based on the command. For e.g., if the command says, “I can see a red and a blue ball; please give me the blue golf ball,” the LSTM can understand that a blue ball should be picked and not a red ball.
However, the main limitation lies in the need for sufficient and diverse training data. Without a wide variety of examples, the LSTM might struggle to generalize and accurately distinguish similar or unseen colors. Additionally, LSTMs can be computationally intensive and might face difficulties when dealing with very long sequences or complex dependencies.
YOLO model:
YOLO is an advanced system designed for real-time object detection in computer vision. Unlike some methods that use multiple steps, YOLO leverages a single powerful neural network. This network processes an image by dividing it into a grid, predicting bounding boxes, and determining class probabilities for objects within each grid cell.
Here’s an explanation of how it works:
Grid System: The image is split into a grid structure, which is responsible for detecting objects within its area.
Bounding Box Prediction: Each object is assigned a bounding box with coordinates and dimensions relative to its grid cell.
Class Prediction: The system estimates the probability that each object belongs to a particular class (e.g., car, person).
Filtering the Best: Finally, the system refines the detections using a technique called non-maximum suppression to remove low-confidence predictions and overlapping boxes, resulting in the most confident object detections.
This efficient and fast approach makes YOLO a valuable tool for various computer vision applications requiring real-time object detection.
MegaPose:
The manipulator arm needs to know exactly where objects are (position and orientation) to interact with them. Megapose6D is the algorithm that gives the 6D pose of a specified object. Accurately determining the 3D location and orientation (6D pose) of objects is crucial for robots and augmented reality. Current methods rely on training with 3D models of the specific objects beforehand. This creates a hurdle for real-world robotics where objects are encountered for the first time and only Computer-aided Design (CAD) models are available. Additionally, generating training data for each object is time-consuming.
MegaPose tackles the challenge of estimating a 6D pose for novel objects, unseen during training. Unlike prior approaches that address limited novelty by focusing on specific object categories, MegaPose aims for complete generalization. Existing methods for novel object pose estimation often rely on non-learning techniques for various steps, limiting their ability to adapt to real-world variations like noise, occlusions, and object diversity.

Two stages of pose refinement
This method proposes extending a learning-based approach used for known objects to handle novel objects. It breaks down the problem into three stages: object detection (in our case, YOLOv8), coarse pose estimation, and refinement through rendering and comparison.
Moveit2:
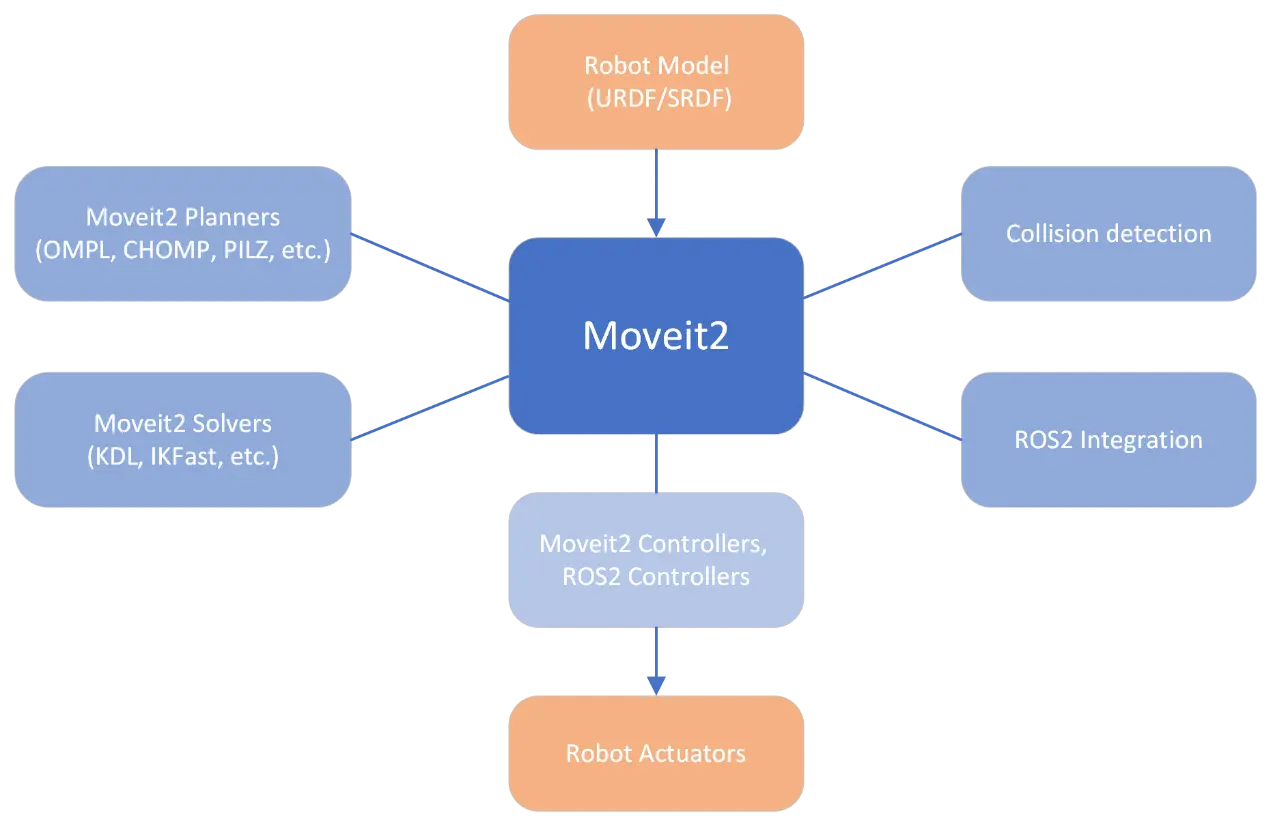
Key functionalities of Moveit2
MoveIt2 is a powerful framework for robotic manipulators (arms) built on ROS2. It acts like the robot’s brain, planning and executing complex movements. Here’s how it works:
Understanding the Robot: It uses URDF [7] (physical structure) and SRDF [8] (semantics like joint limits) to grasp the robot’s capabilities.
Planning the Path: MoveIt2 employs various planners (OMPL, CHOMP, and more) to find safe and efficient paths for the robot arm to reach its target location.
Moving the Robot: Solvers (KDL, IKFast) translate the planned path into specific joint configurations, instructing the robot arm how to move.
Bringing the Plan to Life: Controllers (ROS2 and MoveIt) work together. ROS2 controllers handle low-level motor control while MoveIt controllers bridge the gap between high-level plans and low-level control.
Think of MoveIt2 as the robot’s central nervous system – it plans, translates plans into instructions, and executes them for precise and safe robot movements. In our case, after getting 6D pose from MegaPose, Moveit2 gets activated and controls the arm to pick the ball.
Now that we’ve explored the algorithms and their functionalities, let’s witness them in action! We’ll see the entire process come to life in a live demo. Observe the AMR as it receives the goal to retrieve a ball, navigates towards it, picks it up, and finally places it inside a mug.
Conclusion:
This demo shows capabilities of various AI and robotics technologies that empower an Autonomous Mobile Robot (AMR) to understand your spoken commands and complete a task. From speech recognition with Assembly.ai to object detection with YOLO, each step builds upon the previous one. Navigation with Nav2 utilizes the object’s location to find the most efficient path, while MegaPose precisely estimates the ball’s 3D pose for secure grasping with MoveIt2. This coordinated effort ensures the AMR can not only understand your instructions but also execute them with precision and agility.
Future Work:
While our current system allows for English voice commands, we recognize the importance of global accessibility. The world is becoming increasingly interconnected, and we want to ensure our AMR can be used by everyone, regardless of their native language.
To address this, we want to introduce a new element to the pipeline: a Large Language Model (LLM) [9]. This advanced tool will allow our AMR to understand and react to commands in various languages. This will significantly enhance user-friendliness and broaden the applications that our technology could have.
Know More: Robotic Process Automation
References:
- https://docs.ros.org/en/galactic/index.html
- RC Staudemeyer, ER Morris, “Understanding LSTM — a tutorial into Long Short-Term Memory Recurrent Neural Networks”, arXiv preprint arXiv:1909.09586, 2019.
- Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, “You Only Look Once: Unified, Real-Time Object Detection”, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788.
- https://www.cloudflare.com/learning/ai/what-is-large-language-model/








