In the ever-evolving landscape of microservices architecture, organizations face significant challenges in ensuring the seamless integration, observability, and scalability of their distributed systems.
As businesses increasingly adopt microservices to enhance flexibility and maintainability, they encounter critical issues related to understanding, optimizing, and troubleshooting the complex interactions within their applications.
The lack of comprehensive visibility into the flow of requests, combined with challenges in handling persistent data effectively, hinders the full realization of the benefits promised by microservices.
Some of the challenges are limited observability, troublesome debugging and maintenance, scalability and persistence concerns, and lack of standardized integration.
- Microservices offer scalability, agility, and maintainability in modern application development. With organizations adopting microservices, managing distributed systems’ complexity becomes crucial.
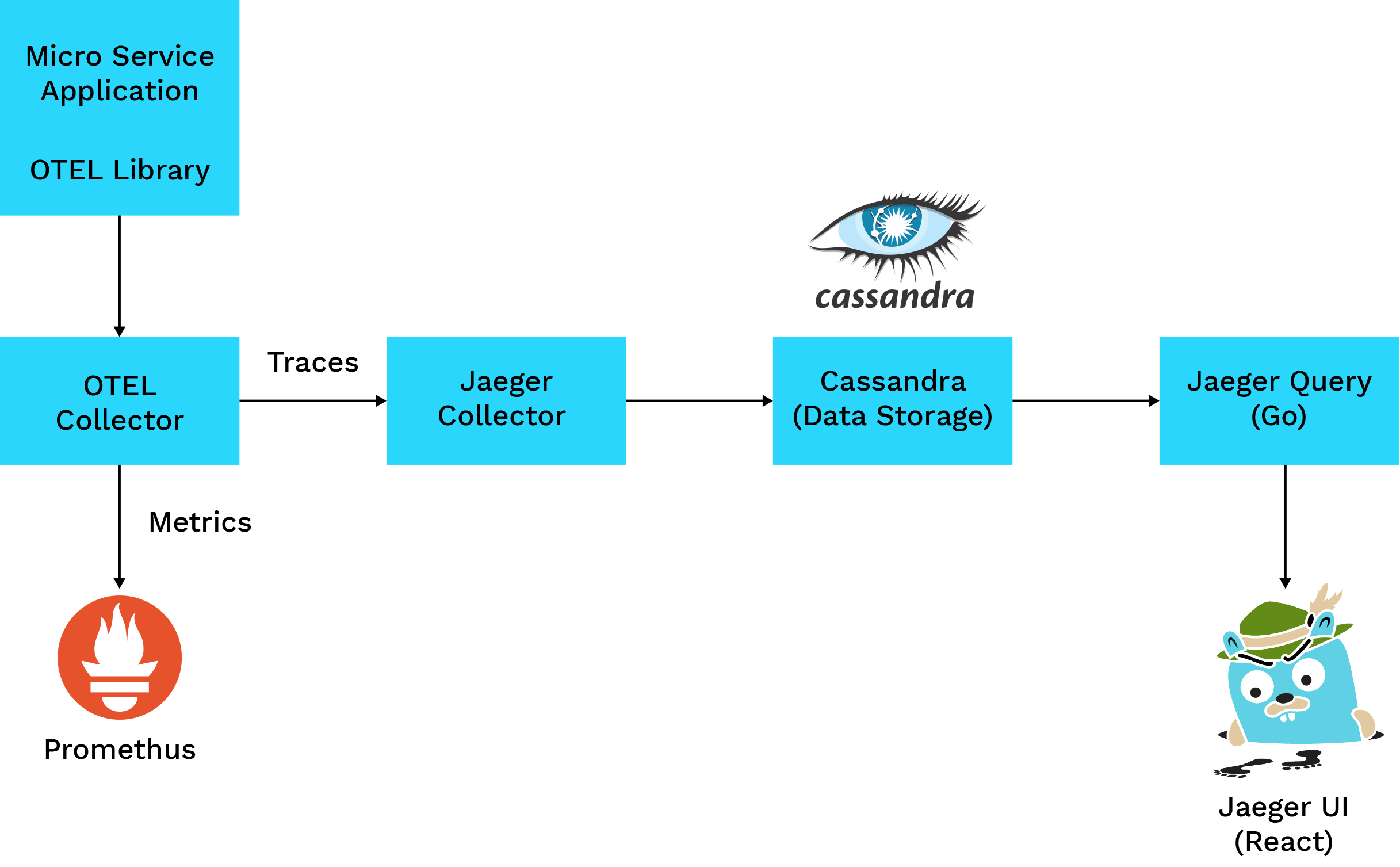
- Jaeger – a distributed tracing system. It is an open-source tracing system that plays a pivotal role by providing visibility into microservices’ request flow, facilitating optimization, troubleshooting, and debugging.
- Cassandra – a highly scalable NoSQL database, empowering microservices architectures. It is a fault-tolerant NoSQL database and seamlessly addresses data persistence challenges in microservices architectures. Its distributed architecture and scalability make it ideal for microservices demanding reliability.
Microservices provide flexibility but pose challenges in performance optimization. Robust observability tools are essential to understand interactions and diagnose issues.
Integrating AKS with Jaegar and Cassandra unlocks microservices’ full potential. From setup to advanced use cases, this initiative empowers developers, architects, and operators in building resilient, high-performance microservices architectures.
Jaeger
Jaeger, a powerful open-source tool, provides end-to-end distributed tracing for applications. By offering visibility into the flow of requests between microservices, Jaeger enables developers and operators to trace and analyze transactions across the entire application stack. Its user-friendly interface and detailed trace information make it an invaluable asset for enhancing observability in complex, distributed systems.
Cassandra
Cassandra, a highly scalable NoSQL database, is designed for distributed and fault-tolerant data storage. With its decentralized architecture, it excels in handling large volumes of data while maintaining high availability. Its ability to seamlessly integrate into distributed systems makes it a powerful solution for persistent data storage, ensuring robustness and resilience in the face of evolving application requirements.
A step-by-step guide on setting up Jaeger and Cassandra in an AKS environment.
- Login into the AKS
az aks get-credentials –resource-group {{ResourceGroupName}} –name {{AKSName}}
- Create the namespace if required
kubectl create namespace {{NamespaceName}}
- Install Cassandra using the helm command
helm repo add bitnami https://charts.bitnami.com/bitnami -n {{NamespaceName}}
help repo update
helm install cassandra bitnami/cassandra -n {{NamespaceName}}
- Collect the password for the Cassandra data source
[System.Text.Encoding]::UTF8.GetString([System.Convert]::FromBase64String($(kubectl get secret –namespace “{{NamespaceName}}” cassandra -o jsonpath=”{.data.cassandra-password}”)))
- Collect the Cassandra Host IP Address for the Cassandra data source
kubectl get service cassandra -o jsonpath='{.spec.clusterIP}’ -n {{NamespaceName}}
you will get the {{CassandraHost}}
- Connect the Cassandra to open non-SQL database
kubectl port-forward svc/cassandra –namespace {{NamespaceName}} 9042:9042
UserName: cassandra
Password: {{Password}}
execute the script: jaeger_v1_schema.cql
- Update CASSANDRA_HOST & CASSANDRA_PASSWORD in the deployment file. Download jaeger-deployment.yaml
- Install and configure Jaeger using the Jaeger deployment file
kubectl apply -f .\jaeger-deployment.yaml -n {{NamespaceName}}
- Access the Jaeger UI
kubectl port-forward svc/jaeger 16686:16686 4317:4317 -n {{NamespaceName}}
Best Practices
Jaeger Best Practices
Jaeger is a powerful distributed tracing system, and implementing it effectively involves following the best practices to ensure optimal performance, scalability, and usability.
Here are some Jaeger best practices.

- Establish Clear Objectives
Clearly define your objectives for implementing Jaeger. Understand the specific use cases, performance goals, and areas of the application that need improved visibility.
- Recognize the Overhead
Distributed tracing introduces some overhead. Be aware of the impact on your application’s performance and carefully choose the sampling strategy (e.g., probabilistic, rate-based) that balances the need for data and system performance.
- Instrumentation Techniques
Adopt a consistent and comprehensive instrumentation strategy. Instrument the critical paths of your application to gain insights into key transactions and workflows.
- Version Harmony
Ensure that your Jaeger components (agents, collectors, storage backend, and UI) are compatible with each other. Regularly update to the latest stable versions to benefit from bug fixes, improvements, and new features.
- Reduce the Volume of Trace Data
Consider the volume of trace data generated, especially in high-throughput systems. Use sampling to control the amount of data collected, preventing excessive storage requirements, and reducing the load on Jaeger components.
- Select an Appropriate Storage
Select a storage backend that aligns with your scalability and performance requirements. Common choices include Elasticsearch, Cassandra, and Kafka. Each has its strengths, so choose one based on your specific needs.
- Security Thought
Implement proper security measures, especially when exposing the Jaeger components to external networks. Use encryption, authentication, and authorization mechanisms to protect sensitive trace data.
- Frequent Maintenance
Perform regular maintenance tasks, such as cleaning up old traces and optimizing storage backends. This ensures efficient resource utilization and prevents unnecessary data retention.
- Alerting and Monitoring
Implement monitoring and alerting for the Jaeger components. Set up alerts for unusual patterns, errors, or performance issues to proactively address potential problems.
- Documentation
Document your Jaeger setup, configuration, and best practices for your team. Provide training to ensure that developers, operators, and other stakeholders are aware of how to effectively use Jaeger for troubleshooting and optimization.
- Integration with Logging and Metrics
Integrate Jaeger with logging and metrics systems. Combining traces with logs and metrics provides a holistic view of system behavior, aiding in comprehensive debugging and performance analysis.
- Backup and Recovery
Implement backup and disaster recovery strategies for your Jaeger storage backend to ensure data integrity and availability in case of failures.
Cassandra Best Practices
Apache Cassandra is a highly scalable NoSQL database designed for handling large volumes of data across distributed clusters. To optimize the performance, reliability, and maintainability of Cassandra, it’s essential to follow best practices. Here are some Cassandra best practices.

- Data Modeling Based on Queries
Design your data model based on your specific queries. Cassandra’s data model should align with the queries you intend to perform to maximize efficiency.
- Denormalization for Query Performance
Denormalize data when necessary to support query patterns. Cassandra’s data model encourages duplication of data to optimize read performance.
- Understand and Leverage Partition Key
Choose an appropriate partition key that evenly distributes data across nodes. Understanding the partition key is crucial for efficient data distribution and retrieval.
- Use Time Window Compaction Strategy
For time-series data, consider using the Time Window Compaction Strategy (TWCS). It’s designed to efficiently handle time-series data with automatic compaction based on time intervals.
- Monitor and Optimize Compaction
Monitor compaction activities and their performance. Adjust compaction-related parameters such as throughput, concurrent compactions, and compaction strategies based on workload and system resources. Also, regularly compact tables to reclaim disk space and optimize performance. Tune compaction strategies based on your workload and data patterns.
- Regularly Update and Patch
Stay current with Cassandra releases and apply patches regularly to benefit from bug fixes, performance improvements, and new features.
- Backup and Restore Strategies
Implement and regularly test backup and restore strategies. Ensure that you have a reliable mechanism for data recovery in case of failures or data loss.
- Network Configuration
Optimize network configuration, including settings for inter-node communication and internode encryption. Ensure low-latency and reliable communication between nodes.
Conclusion
Integrating Jaeger and Cassandra into an Azure Kubernetes Service (AKS) environment for microservices offers a powerful solution for enhancing observability, scalability, and reliability. The combination of these two technologies addresses critical challenges in distributed systems, providing a comprehensive approach to traceability, data management, and performance optimization.





