Introduction
Businesses are continuously looking for methods to use the power of real-time data for actionable insights and decision-making in the fast-paced world of contemporary technology. Apache Kafka is an open-source distributed event streaming technology that has revolutionized real-time data processing. We will examine the capabilities, design, and uses of Apache Kafka in this blog post, examining why it has grown to be a vital tool for enterprises tackling the difficulties associated with managing massive amounts of streaming data.
An internal initiative at LinkedIn began the development of Apache Kafka, an open-source distributed event streaming platform, to meet the changing demands of real-time data processing. Later, after realizing Kafka’s potential and importance, LinkedIn contributed it to the Apache Software Foundation by making it open-source. This action promoted communal cooperation, which aided in its broad acceptance and further improvement.
Problem Statement
Building scalable, distributed, and fault-tolerant systems and managing real-time data streams present several issues that Apache Kafka tries to solve. Organizations must deal with an enormous rise in data creation from a variety of sources, including devices, apps, and services, in today’s fast-paced technology environment. The current methods are unable to address the several problems presented by the flood of real-time data. A reliable, scalable, and fault-tolerant system is crucial in this situation.
What is Apache Kafka?
Many different sectors utilize Apache Kafka extensively for event-driven architecture construction, log aggregation, monitoring, and real-time data streaming. Organizations handling large-scale, mission-critical data applications frequently choose it because of its fault tolerance, scalability, and support for real-time stream processing.
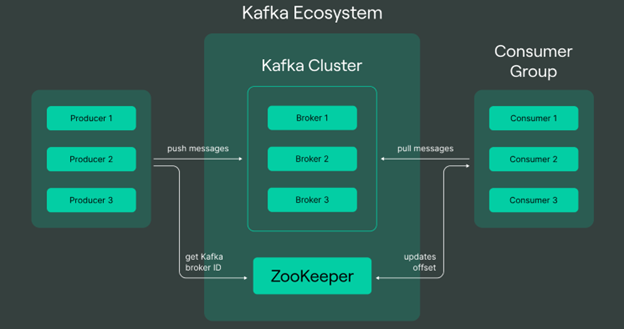
These are some of the main ideas and elements of Apache Kafka:
- Topics: Data in Kafka is arranged logically into topics, which serve as a conduit for messages.
- Producers: Publicizing statements on Kafka-related topics is the responsibility of producers. These might be any kind of systems or applications that produce data and send it to Kafka server for process.
- Consumers: Customers digest the messages posted to the subjects they subscribe to. When it comes to deriving conclusions or acting on real-time data, they are essential.
- Brokers: Kafka operates in a distributed architecture where multiple servers, known as brokers, form a Kafka cluster. Brokers oversee answering client requests, maintaining fault tolerance, and storing and managing the data.
- Partitions: There are partitions for each topic, and a log is inside each partition. Kafka uses partitions to split the load across several brokers and consumers and process the messages in parallel.
- Replication: Kafka replicates data among many brokers, ensuring fault tolerance. There is one leader and several clones for every division. Data availability may be guaranteed if a broker fails by having one of the copies assume leadership.
- Zookeeper: To handle the dispersed nature of the Kafka cluster, Kafka makes use of Apache ZooKeeper. The election of the Kafka brokers’ leaders, their setup, and their synchronization are all handled by the ZooKeeper.
- Log Compaction: Kafka supports log compaction, a feature that retains only the latest version of each record in a partition. This is particularly useful for scenarios where you want to keep a compacted version of the data, such as maintaining a changelog.
- Streams API: Kafka provides Streams API for building stream processing applications. With this API, developers can create robust and scalable real-time applications that process data as it flows through Kafka topics.
- Connect API: Kafka Connect is an API for building connectors that facilitate the integration of Kafka with external systems. Connectors allow data to be ingested from or exported to various sources and sinks.
Benefits Of Apache Kafka
- Publish-Subscribe Message System: With Kafka, producers post messages to topics and consumers subscribe to those topics to receive them. This is known as a publish-subscribe paradigm.
- Distributed Architecture: Kafka is designed to operate as a distributed system, allowing it to scale horizontally across multiple nodes or servers. High availability and fault tolerance are ensured by this distributed design.
- Fault Tolerance: Kafka distributes data replication over several brokers, or servers, so that the data remains accessible on other nodes in the event of a broker failure.
- Scalability: The cluster may be expanded horizontally using Kafka by adding more brokers. This allows it to handle increasing data volumes and processing demands.
- Durability: Kafka provides durable storage of messages, allowing them to persist on disk. Because of its endurance, messages are preserved even in the event of a node failure.
- High Throughput: Kafka is optimized for high throughput, making it suitable for scenarios with a large number of messages per second.
- Stream Processing: Because stream processing is supported natively by Kafka, developers may create real-time applications that can process and analyze data as it comes into the system.
Use Cases and Applications
1. Financial Services
- Use Case: Real-time Transaction Processing
- Description: Financial institutions leverage Apache Kafka to process and analyze real-time transaction data. This entails keeping an eye on stock deals, handling financial transactions, and quickly identifying fraudulent activity.
- Use Case: Market Data Feeds
- Description: Kafka is used to handle high throughput market data feeds, allowing financial organizations to consume and analyze real-time data from various sources, including stock exchanges and financial markets.
2. Retail and E-Commerce
- Use Case: Inventory Management
- Description: Retailers use Apache Kafka for real-time inventory management. Events such as product sales, restocking, and order processing are streamed to efficiently manage inventory levels and make data-driven restocking decisions.
- Use Case: Personalized Marketing
- Description: E-commerce platforms utilize Kafka to process user behavior data in real time. They can now offer tailored suggestions, focused promotions, and dynamic pricing depending on how customers engage with them, thanks to this.
3. Telecommunications
- Use Case: Call Detail Records (CDR) Processing
- Description: Telecom companies leverage Apache Kafka for processing and analyzing call detail records in real-time. This includes tracking call patterns, monitoring network performance, and detecting anomalies.
- Use Case: Event-Driven Architectures
- Description: Kafka is used to implement event-driven architectures in telecommunications, enabling the real-time processing of events such as network faults, billing updates, and subscriber activities.
4. Healthcare
- Use Case: Patient Monitoring
- Description: Healthcare organizations use Kafka for real-time patient monitoring. It enables the streaming of data from medical devices, monitoring systems, and electronic health records to provide timely alerts and ensure patient safety.
- Use Case: Data Integration in Healthcare Systems
- Description: Kafka is employed for data integration across diverse healthcare systems. It facilitates the real-time exchange of information between electronic health records, diagnostic systems, and other healthcare applications.
5. Logistics and Supply Chain
- Use Case: Supply Chain Visibility
- Description: Logistics companies utilize Kafka for real-time tracking of shipments and inventory. Events such as order fulfillment, shipping updates, and inventory changes are streamed to enhance supply chain visibility.
- Use Case: Fleet Management
- Description: Kafka is employed in fleet management systems to process and analyze real-time data from vehicles, ensuring efficient route optimization, monitoring driver behavior, and enhancing overall fleet performance.
6. Media and Entertainment
- Use Case: Content Streaming and Recommendations
- Description: Media streaming platforms use Kafka to handle real-time data from user interactions. It enables content recommendations, personalized playlists, and real-time adjustments to streaming quality.
- Use Case: User Engagement Analytics
- Description: Kafka is employed for tracking user engagement in media and entertainment applications. Understanding user behavior, streamlining the distribution of information, and improving the user experience – all benefit from real-time analytics.
7. Manufacturing and IoT
- Use Case: Predictive Maintenance
- Description: Manufacturing companies use Kafka for real-time monitoring of industrial equipment. Through sensor data analysis, anomaly detection, and maintenance alert triggering, it makes predictive maintenance easier.
- Use Case: IoT Data Ingestion and Processing
- Description: Kafka is a preferred choice for handling large volumes of data from IoT devices. It enables the real-time ingestion and processing of sensor data, facilitating applications like smart cities, smart buildings, and industrial IoT.
8. Gaming
- Use Case: Real-Time Game Analytics
- Description: Online gaming platforms use Kafka to process real-time game analytics. It enables the tracking of player interactions, in-game events, and facilitates the delivery of personalized gaming experiences.
- Use Case: Event Sourcing in Gaming Applications
- Description: Kafka is employed for event sourcing in gaming applications, recording and processing in-game events, player actions, and game state changes in real-time.
Conclusion
In conclusion, Apache Kafka stands as a versatile and powerful solution for organizations seeking to navigate the complexities of real-time data processing and event-driven architectures. Its open-source nature, coupled with a vibrant community, ensures ongoing development and innovation, making Kafka a cornerstone in the landscape of distributed event streaming platforms.






