Eine typische Entwicklungspipeline für Deep-Learning-Modelle umfasst die Datenerfassung, die Datenaufbereitung, das Modelltraining, das Leistungsbenchmarking des Modells, die Optimierung des Modells und schließlich die Bereitstellung des Modells auf dem Zielgerät. Da ein Deep-Learning-Modell die Darstellung direkt aus den Daten lernt, können wir sagen, dass die Leistung umso besser ist, je mehr Daten wir haben.
Die manuelle Erfassung einer so großen Datenmenge, die alle Varianten enthält, ist eine mühsame Aufgabe. Außerdem ist die Kommentierung einer so großen Datenmenge ebenfalls sehr zeit- und arbeitsintensiv. Um dieses Problem zu lösen, hat Nvidia einen Simulator (Isaac Simulator) entwickelt, der ML-Ingenieuren (Machine Learning) dabei helfen kann, große, kommentierte Datensätze zu erstellen.
Um einen Bilddatensatz aus dem Isaac-Simulator zu erfassen, importieren wir eine mit dem Blender-Tool erstellte Szene. Nach dem Import der Szene und anderer erforderlicher Objektmodelldateien in den Simulator können wir verschiedene Zufallseinstellungen wie Textur und Beleuchtung vornehmen, um reale Variationen in den Datensatz einzubeziehen. Der generierte Datensatz wird dann für das Training des DL-Modells mit Hilfe des von Nvidia bereitgestellten TAO-Toolkits verwendet. Das TAO-Toolkit ist eine Komplettlösung zum Trainieren, Erweitern und Optimieren des Modells. Man kann das mit dem TAO-Toolkit trainierte Modell im .trt- oder .plan-Format exportieren, das auf dem TensorRT- oder Triton-Ausführungsserver ausgeführt werden kann. In diesem Blog werden wir uns diese Tools im Detail ansehen und erfahren, wie wir sie für das Training und den Einsatz eines Deep-Learning-Modells nutzen können.
Wir haben einen synthetischen Trainingsdatensatz mit Blender und dem Isaac-Simulator erstellt. Blender ist ein kostenloses und quelloffenes 3D-Erstellungsprogramm, das die gesamte 3D-Pipeline unterstützt, einschließlich Modellierung, Rigging, Animation, Simulation und Rendering. Die mit Blender erstellte Szene wird dann in den Isaac-Simulator importiert. NVIDIA Isaac Sim™ ist eine skalierbare Robotersimulationsanwendung und ein Tool zur Generierung synthetischer Daten, das umfangreiche Tools für die Generierung synthetischer Daten bietet, wie z. B. Domain Randomization, Ground Truth Labeling, Segmentierung und Bounding Boxes.
Weitere Einzelheiten zur Erzeugung synthetischer Daten mit Isaac sim finden Sie im folgenden Blog: Vom Konzept zur Fertigstellung: Rationalisierung der 3D-Szenenerstellung für die Robotik mit Nvidia Isaac Sim und Blender
Wenn wir mit einem nichtlinearen System wie einem AMR arbeiten, müssen wir einige Änderungen am Kalman-Filter-Algorithmus vornehmen. Um sicherzustellen, dass unsere Zustandsdarstellung nach jedem Vorhersage- und Aktualisierungsschritt eine Gaußsche Verteilung bleibt, müssen wir die Bewegungs- und Messmodelle linearisieren. Dies geschieht durch die Verwendung von Taylor-Reihen, um die nichtlinearen Modelle als lineare Modelle zu approximieren. Diese Erweiterung des Kalman-Filters wird als Erweiterter Kalman-Filter bezeichnet.
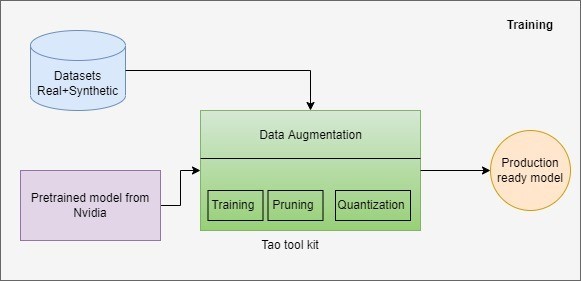
Nvidia bietet eine Low-Code-Lösung an, die es Entwicklern und Unternehmen ermöglicht, das Training und die Optimierung von Modellen zu beschleunigen: das TAO-Toolkit. Das TAO-Toolkit hilft Einsteigern, indem es die Komplexität von KI-Modellen und Deep-Learning-Frameworks abstrahiert. Mit dem NVIDIA TAO Toolkit können wir die Leistung des Transfer-Learnings nutzen und die von NVIDIA vortrainierten Modelle mit unseren eigenen Daten feinabstimmen und das Modell für die Inferenz optimieren.
Das TAO-Toolkit bietet zahlreiche vortrainierte Computer Vision Modelle für Objekterkennung, Bildklassifikation, Segmentierung und Konversations-KI. Modelle, die mit dem TAO-Toolkit erzeugt werden, sind vollständig kompatibel mit und beschleunigt für TensorRT, was maximale Inferenzleistung ohne zusätzlichen Aufwand gewährleistet.
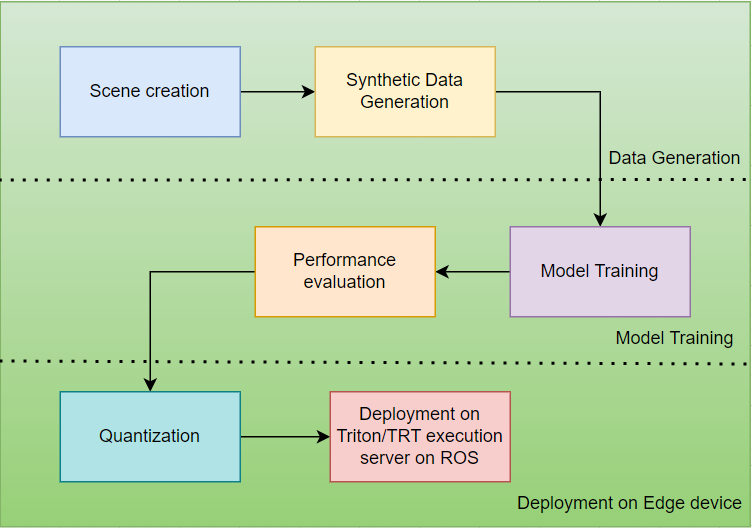
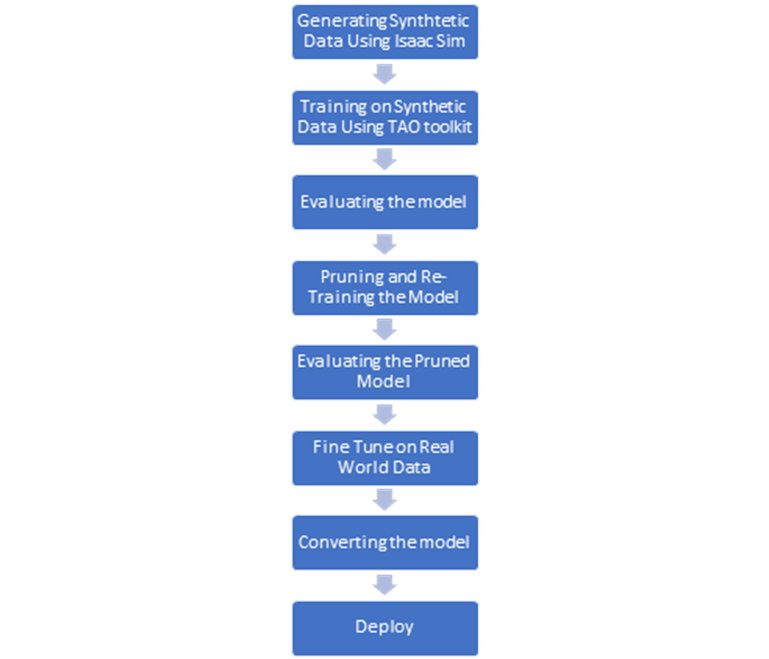
Unsere Trainingspipeline nutzt das Nvidia TAO-Toolkit für eine effiziente und schnelle Entwicklung des Modells. Der Arbeitsablauf von der Erzeugung synthetischer Daten bis zum Einsatz ist unten dargestellt:
Beim Training des Modells mit dem TAO-Toolkit ist zu beachten, dass alle Ressourcen/Assets, die in der gesamten TAO-Pipeline verwendet werden, in den TAO-Docker-Container eingebunden und von dort aus genutzt werden. Während des Trainings werden Umgebungsvariablen sowohl für den Pfad zum Systemverzeichnis (Quelle) als auch für den Pfad zum TAO-Docker-Container (Ziel) erstellt. Die Datei "mount.json" enthält die Quell- und Zielpfade.
Beim Training ist es wichtig, dass die Dimensionen in allen Spezifikationsdateien bis zum Ende gleich bleiben. Eine zwischenzeitliche Änderung der Dimensionen führt zu falschen Ausgabemetriken (Precision, Recall, MIOU) und schlechter Modellleistung.
Für die Objekterkennung haben wir DetectNetV2 ausgewählt und anhand synthetischer Daten, die mit dem Isaac-Simulator erzeugt wurden, eine Feinabstimmung vorgenommen. Die trainierte Modelldatei wird exportiert und auf der Hardware zur Inferenz eingesetzt. Das Blockdiagramm der Trainingspipeline ist unten dargestellt:
Gazebo ist eine ROS-2-fähige Simulationsumgebung, die eine große Flexibilität für das Testen von Robotersystemen bietet. Sie ermöglicht es uns, Sensorrauschen einzuführen, verschiedene Reibungskoeffizienten auszuprobieren und die Genauigkeit des Raddrehgebers zu verringern, wodurch wir realistische Szenarien nachbilden können, die die Zustandsschätzung eines AMR in der realen Welt beeinflussen würden.
Um die Leistung der Sensorfusion zu quantifizieren, können wir einen Schleifenschlusstest durchführen, bei dem der AMR auf einer zufällig geschlossenen Trajektorie läuft, so dass die Anfangs- und Endposition des AMR identisch sind. Anschließend können wir die Zustandsschätzung durch EKF nach der Fusion von IMU und Raddrehgebern aufzeichnen und mit der Zustandsschätzung anhand der reinen Raddrehgeber vergleichen. Im Idealfall sollte der geschätzte Zustand unseres AMR x, y und yaw jeweils als (0, 0, 0) anzeigen.
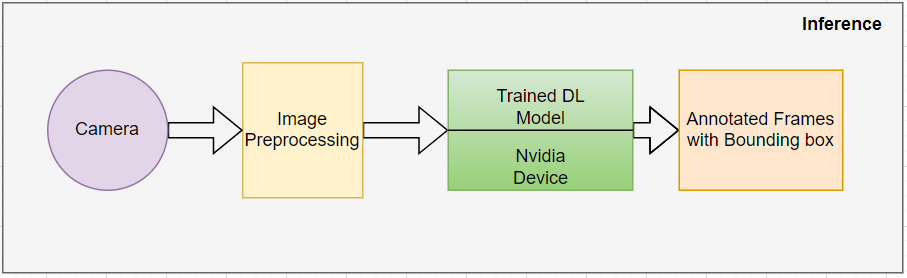
Sobald das Modell die gewünschte Genauigkeit erreicht und alle Leistungsprüfungen bestanden hat, wird es in eine .trt- oder .plan-Datei exportiert. Das exportierte Modell kann auf Nvidia-Edge-Geräten für Echtzeit-Inferenzen eingesetzt werden. Die Inferenzpipeline erwartet RGB-Bilder von der Kamera in Echtzeit und wendet die erforderliche Vorverarbeitung auf das Bild an, um es mit der Eingabegröße des Modells kompatibel zu machen und die gewünschte Leistung/den gewünschten Durchsatz zu erreichen. Das folgende Blockdiagramm zeigt den Inferenzfluss:
In diesem Blog haben wir gesehen, wie wir schnell ein DL-Modell auf synthetischen Daten trainieren und es für Echtzeit-Inferenz einsetzen können. Wir haben das Modell für die Erkennung von Pappkartons auf synthetischen Daten trainiert und eine Genauigkeit von über 90 % in der realen Welt erreicht. In Zukunft möchten wir mit synthetischen Daten und realen Daten experimentieren und sehen, wie sich dies auf die Gesamtleistung des Modells auswirkt.


Pallavi Pansare arbeitet als Solution Engineer bei eInfochips und verfügt über 4 Jahre Erfahrung in Bereichen wie Signalverarbeitung, Bildverarbeitung, Computer Vision, Deep Learning und maschinelles Lernen. Sie hat einen Master-Abschluss in Signalverarbeitung und promoviert derzeit in künstlicher Intelligenz.

ManMohan Tripathi hat einen Master-Abschluss in Künstlicher Intelligenz von der Universität Hyderabad. Er arbeitet derzeit bei eInfochips Inc. als Solution Engineer. Sein Interessengebiet umfasst neuronale Netzwerke, Deep Learning und Computer-Vision-Algorithmen.

eInfochips, ein Unternehmen von Arrow Electronics, ist ein führender Anbieter von Dienstleistungen in den Bereichen digitale Transformation und Produktentwicklung. eInfochips beschleunigt die Markteinführung für seine Kunden mit seinem Fachwissen in den Bereichen IoT, KI/ML, Sicherheit, Sensoren, Silizium, Wireless, Cloud und Energie. eInfochips wurde von vielen Top-Analysten und Branchengremien, darunter Gartner, Zinnov, ISG, IDC, NASSCOM und anderen, als führendes Unternehmen im Bereich technische F&E-Dienstleistungen anerkannt.
Hauptsitz
- USA, San Jose
- INDIEN, Ahmedabad
Schreiben Sie uns: marketing@eInfochips.com
©2025 eInfochips (ein Arrow-Unternehmen), alle Rechte vorbehalten. | Erfahren Sie mehr über die Datenschutzrichtlinie und die Cookie-Richtlinie von Arrow
Vereinbaren Sie einen 30-minütigen Beratungstermin mit unseren Automotive Solution Experts
Vereinbaren Sie einen 30-minütigen Beratungstermin mit unserem Experten für Batteriemanagementlösungen
Vereinbaren Sie einen 30-minütigen Beratungstermin mit unseren Experten für Industrie- und Energielösungen
Vereinbaren Sie einen 30-minütigen Beratungstermin mit unseren Experten
