Un pipeline de développement de modèle d'apprentissage profond typique comprend l'acquisition de données, la préparation des données, l'entraînement du modèle, l'analyse comparative des performances du modèle, l'optimisation du modèle et enfin le déploiement du modèle sur l'appareil cible. Étant donné qu'un modèle d'apprentissage profond apprend la représentation directement à partir des données, nous pouvons dire que plus nous avons de données, meilleures sont les performances.
La saisie manuelle d'une telle quantité de données, incluant toutes les variations, est une tâche fastidieuse. En outre, l'annotation d'une telle quantité de données prend beaucoup de temps et demande beaucoup de travail. Pour résoudre ce problème, Nvidia a produit un simulateur (Isaac Simulator) qui peut aider un ingénieur en ML (Machine Learning) à créer facilement de grands ensembles de données annotées.
Pour capturer un ensemble de données d'images à partir du simulateur Isaac, nous importons une scène créée à l'aide de l'outil Blender. Après avoir importé le fichier modèle de la scène et des autres objets requis dans le simulateur, nous pouvons appliquer diverses randomisations de domaine, telles que la texture et l'éclairage, afin d'incorporer les variations du monde réel dans l'ensemble de données. L'ensemble de données généré est ensuite utilisé pour entraîner le modèle DL à l'aide de la boîte à outils TAO fournie par Nvidia. La boîte à outils TAO est une solution unique pour l'entraînement, l'augmentation et l'optimisation du modèle. Il est possible d'exporter le modèle formé à l'aide de la boîte à outils TAO au format .trt ou .plan exécutable sur le serveur d'exécution TensorRT ou Triton. Dans ce blog, nous verrons ces outils en détail et comment nous pouvons les utiliser pour la formation et le déploiement d'un modèle d'apprentissage profond.
Nous avons créé un ensemble de données d'entraînement synthétiques en utilisant Blender et le simulateur Isaac. Blender est une suite de création 3D libre et gratuite qui prend en charge l'intégralité du pipeline 3D, y compris la modélisation, le truquage, l'animation, la simulation et le rendu. La scène créée à l'aide de Blender est ensuite importée dans le simulateur Isaac. NVIDIA Isaac Sim™ est une application de simulation robotique évolutive et un outil de génération de données synthétiques qui fournit des outils étendus pour la génération de données synthétiques, tels que la randomisation du domaine, l'étiquetage de la vérité terrain, la segmentation et les boîtes de délimitation.
Pour plus de détails sur la génération de données synthétiques à l'aide d'Isaac sim, veuillez consulter le blog suivant : Du concept à la réalisation : Streamlining 3D Scene Creation for Robotics with Nvidia Isaac Sim and Blender (De la conception à la réalisation : rationalisation de la création de scènes 3D pour la robotique avec Nvidia Isaac Sim et Blender)
Lorsqu'on travaille avec un système non linéaire tel qu'un robot mobile autonome (AMR), il faut apporter quelques modifications à l'algorithme du filtre de Kalman. Pour garantir que la représentation de l'état reste une distribution gaussienne après chaque étape de prédiction et de mise à jour, il faut linéariser les modèles de mouvement et de mesure. Pour ce faire, on utilise des séries de Taylor afin d'approximer les modèles non linéaires par des modèles linéaires. Cette extension du filtre de Kalman est appelée « filtre de Kalman étendu ».
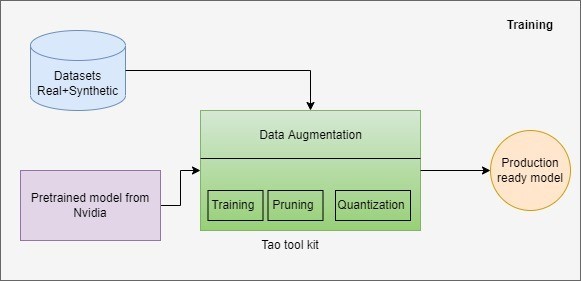
Nvidia propose une solution low-code permettant aux développeurs et aux entreprises d'accélérer les processus d'entraînement et d'optimisation des modèles, appelée TAO toolkit. La boîte à outils TAO aide les débutants en faisant abstraction de la complexité des modèles d'IA et des cadres d'apprentissage profond. Avec le kit d'outils TAO de NVIDIA, nous pouvons utiliser la puissance de l'apprentissage par transfert et affiner les modèles pré-entraînés de NVIDIA avec nos propres données et optimiser le modèle pour l'inférence.
La boîte à outils TAO fournit de nombreux modèles pré-entraînés de vision artificielle pour la détection d'objets, la classification d'images, la segmentation et l'intelligence artificielle des conversations. Les modèles générés avec la boîte à outils TAO sont entièrement compatibles et accélérés pour TensorRT, ce qui garantit des performances d'inférence maximales sans aucun effort supplémentaire.
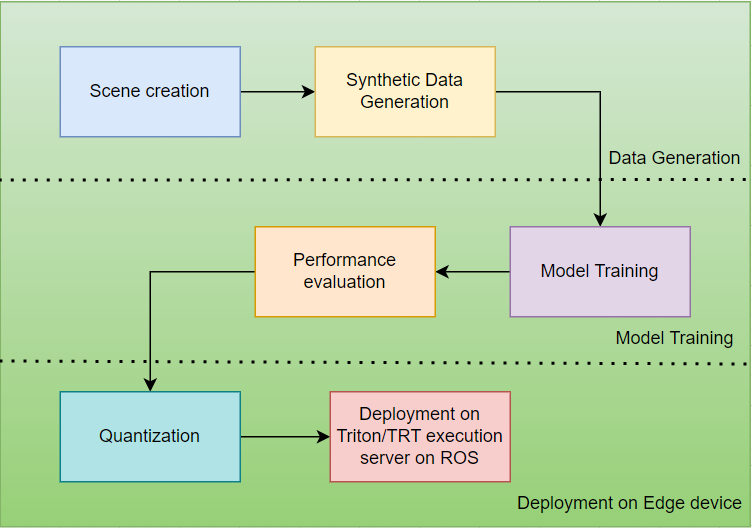
Notre pipeline de formation exploite la boîte à outils Nvidia TAO pour un développement efficace et rapide du modèle. Le flux de travail, de la génération de données synthétiques au déploiement, est illustré ci-dessous :
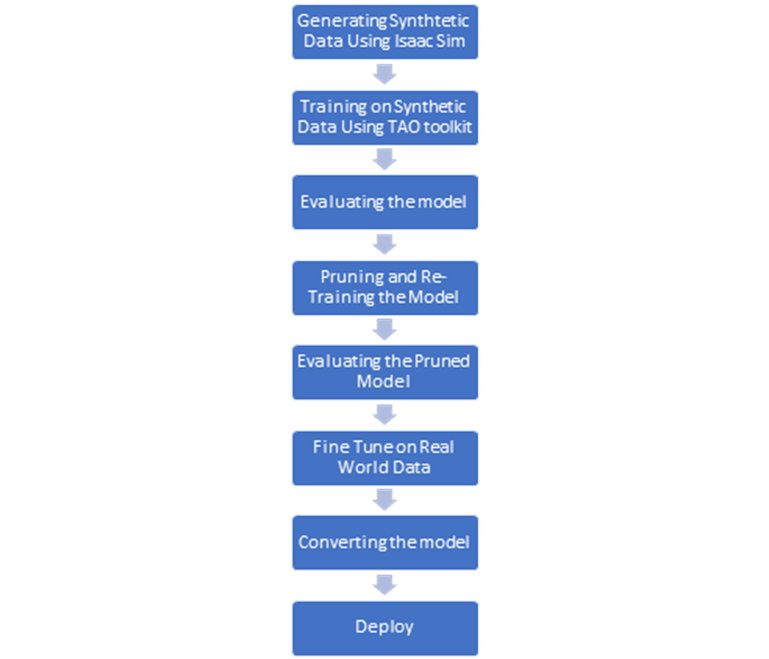
Lors de l'apprentissage du modèle à l'aide de la boîte à outils TAO, il est important de noter que toutes les ressources/actifs qui seront utilisés tout au long du pipeline TAO seront montés sur le conteneur Docker TAO et seront utilisés à partir de là. Pendant la formation, des variables d'environnement sont créées à la fois pour le chemin du répertoire système (source) et le chemin du conteneur Docker TAO (destination). Le fichier "mount.json" contient les chemins d'accès à la source et à la destination.
Pendant l'entraînement, il est important de conserver les mêmes dimensions dans tous les fichiers de spécification jusqu'à la fin. Tout changement de dimension entre-temps se traduira par des mesures de sortie erronées (précision, rappel, MIOU) et par de mauvaises performances du modèle.
Pour la tâche de détection d'objets, nous avons sélectionné DetectNetV2 et l'avons affiné sur des données synthétiques générées par le simulateur Isaac. Le fichier du modèle entraîné est exporté et déployé sur le matériel pour l'inférence. Le schéma fonctionnel du pipeline de formation est représenté ci-dessous :
Gazebo est un environnement de simulation compatible avec ROS 2 qui offre une grande flexibilité pour tester des systèmes robotiques. Il permet d'introduire du bruit de capteur, d'essayer différents coefficients de frottement et de réduire la précision des codeurs de roue, ce qui permet de reproduire des scénarios réalistes susceptibles d'influencer l'estimation d'état d'un robot mobile autonome (AMR) dans le monde réel.
Pour quantifier les performances de la fusion de capteurs, nous pouvons effectuer un test de boucle fermée, qui consiste à faire suivre à l'AMR une trajectoire fermée aléatoire de telle sorte que sa position initiale et sa position finale coïncident. Nous pouvons ensuite tracer l'estimation d'état effectuée par l'EKF après fusion des données de l'IMU et des codeurs de roue, et la comparer à l'estimation d'état réalisée à partir des données brutes des codeurs de roue. Idéalement, nous souhaitons que l'état estimé de notre AMR indique respectivement x, y et le lacet comme étant (0, 0, 0).
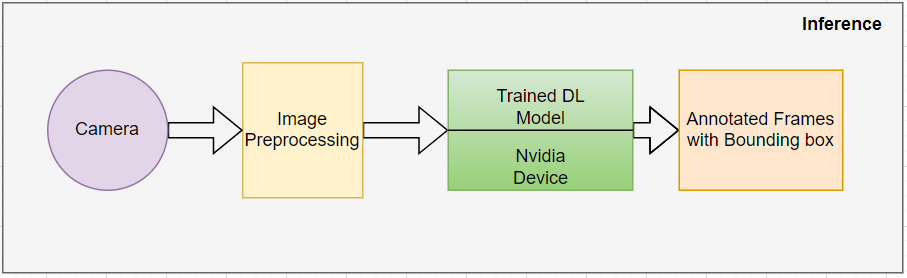
Une fois que le modèle atteint la précision souhaitée et passe tous les contrôles de performance, il est exporté dans un fichier .trt ou .plan. Le modèle exporté peut être déployé sur les périphériques Nvidia pour une inférence en temps réel. Le pipeline d'inférence attend les images RVB provenant de la caméra en temps réel et applique le prétraitement requis à l'image pour la rendre compatible avec la taille d'entrée du modèle et atteindre les performances/le débit souhaités. Le schéma fonctionnel ci-dessous décrit le flux d'inférence :
Dans ce blog, nous avons vu comment nous pouvons rapidement entraîner un modèle DL sur des données synthétiques et le déployer pour l'inférence en temps réel. Nous avons entraîné le modèle de détection des cartons sur des données synthétiques et obtenu une précision de plus de 90 % dans le monde réel. Dans nos travaux futurs, nous aimerions expérimenter en mélangeant des données synthétiques avec des données réelles et voir comment cela affecte les performances globales du modèle.


Pallavi Pansare travaille en tant qu'ingénieur solution chez eInfochips avec plus de 4 ans d'expertise dans des domaines tels que le traitement du signal, le traitement de l'image, la vision par ordinateur, l'apprentissage profond et l'apprentissage automatique. Elle est titulaire d'un master en traitement du signal et poursuit actuellement son doctorat en intelligence artificielle.

ManMohan Tripathi est titulaire d'une maîtrise en intelligence artificielle de l'université d'Hyderabad. Il travaille actuellement chez eInfochips Inc en tant qu'ingénieur en solutions. Son domaine d'intérêt comprend les réseaux neuronaux, l'apprentissage profond et les algorithmes de vision par ordinateur.
Prenez rendez-vous pour une consultation de 30 minutes avec nos experts en solutions automobiles
Prenez rendez-vous pour une consultation de 30 minutes avec notre expert en solutions de gestion de batteries
Prenez rendez-vous pour une consultation de 30 minutes avec nos expertsen solutions industrielles et énergétiques
Prenez rendez-vous pour une consultation de 30 minutes avec nos experts
