Einführung
Unternehmen sind ständig auf der Suche nach Methoden, um die Leistungsfähigkeit von Echtzeitdaten für verwertbare Erkenntnisse und Entscheidungen in der schnelllebigen Welt der modernen Technologie zu nutzen. Apache Kafka ist eine Open-Source-Technologie für verteiltes Ereignis-Streaming, die die Echtzeit-Datenverarbeitung revolutioniert hat. In diesem Blog-Beitrag werden wir die Fähigkeiten, das Design und die Einsatzmöglichkeiten von Apache Kafka untersuchen und herausfinden, warum es sich zu einem wichtigen Tool für Unternehmen entwickelt hat, die mit den Schwierigkeiten bei der Verwaltung großer Mengen von Streaming-Daten konfrontiert sind.
Eine interne Initiative bei LinkedIn begann mit der Entwicklung von Apache Kafka, einer Open-Source-Plattform für verteiltes Ereignis-Streaming, um den sich ändernden Anforderungen der Echtzeit-Datenverarbeitung gerecht zu werden. Später, nachdem LinkedIn das Potenzial und die Bedeutung von Kafka erkannt hatte, stellte es der Apache Software Foundation zur Verfügung und machte es zu Open Source. Diese Maßnahme förderte die gemeinschaftliche Zusammenarbeit, was zu einer breiten Akzeptanz und weiteren Verbesserung beitrug.
Problemstellung
Der Aufbau skalierbarer, verteilter und fehlertoleranter Systeme und die Verwaltung von Echtzeit-Datenströmen stellen mehrere Probleme dar, die Apache Kafka zu lösen versucht. In der heutigen schnelllebigen Technologieumgebung müssen Unternehmen mit einem enormen Anstieg der Datenerzeugung aus einer Vielzahl von Quellen, einschließlich Geräten, Anwendungen und Diensten, umgehen. Die aktuellen Methoden sind nicht in der Lage, die verschiedenen Probleme zu bewältigen, die durch die Flut von Echtzeitdaten entstehen. Ein zuverlässiges, skalierbares und fehlertolerantes System ist in dieser Situation entscheidend.
Was ist Apache Kafka?
Apache Kafka wird in vielen verschiedenen Bereichen für den Aufbau ereignisgesteuerter Architekturen, die Aggregation von Protokollen, die Überwachung und das Streaming von Echtzeitdaten eingesetzt. Organisationen, die mit großen, unternehmenskritischen Datenanwendungen arbeiten, entscheiden sich häufig für Kafka, weil es Fehlertoleranz, Skalierbarkeit und Unterstützung für Echtzeit-Datenstromverarbeitung bietet.
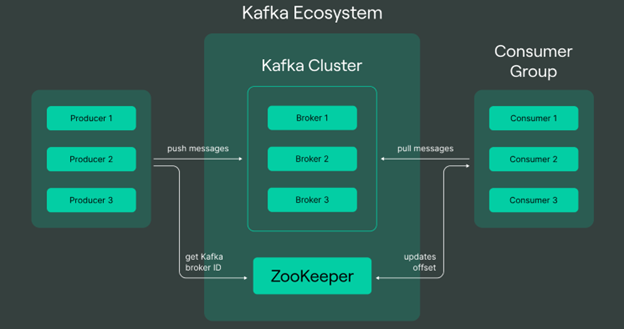
Dies sind einige der wichtigsten Ideen und Elemente von Apache Kafka:
- Themen: Die Daten in Kafka sind logisch in Topics angeordnet, die als Kanal für Nachrichten dienen.
- Produzenten: Die Veröffentlichung von Aussagen zu Kafka-bezogenen Themen liegt in der Verantwortung der Produzenten. Dabei kann es sich um jede Art von Systemen oder Anwendungen handeln, die Daten produzieren und diese zur Verarbeitung an den Kafka-Server senden.
- Verbraucher: Die Kunden verdauen die Nachrichten, die zu den von ihnen abonnierten Themen veröffentlicht werden. Wenn es darum geht, Schlussfolgerungen zu ziehen oder auf der Grundlage von Echtzeitdaten zu handeln, sind sie unverzichtbar.
- Makler: Kafka arbeitet in einer verteilten Architektur, in der mehrere Server, so genannte Broker, einen Kafka-Cluster bilden. Die Broker sind für die Beantwortung von Kundenanfragen, die Aufrechterhaltung der Fehlertoleranz sowie die Speicherung und Verwaltung der Daten zuständig.
- Partitionen: Für jedes Thema gibt es Partitionen, und in jeder Partition befindet sich ein Protokoll. Kafka verwendet Partitionen, um die Last auf mehrere Broker und Verbraucher zu verteilen und die Nachrichten parallel zu verarbeiten.
- Replikation: Kafka repliziert die Daten zwischen vielen Brokern und gewährleistet so Fehlertoleranz. Für jede Abteilung gibt es einen Leader und mehrere Klone. Die Datenverfügbarkeit kann beim Ausfall eines Brokers gewährleistet werden, indem eine der Kopien die Führung übernimmt.
- Zookeeper: Um die verteilte Natur des Kafka-Clusters zu handhaben, nutzt Kafka den Apache ZooKeeper. Die Wahl der Leiter der Kafka-Broker, ihre Einrichtung und ihre Synchronisierung werden vom ZooKeeper übernommen.
- Log-Verdichtung: Kafka unterstützt die Protokollverdichtung, eine Funktion, die nur die letzte Version eines jeden Datensatzes in einer Partition beibehält. Dies ist besonders nützlich für Szenarien, in denen Sie eine komprimierte Version der Daten aufbewahren möchten, z. B. bei der Pflege eines Änderungsprotokolls.
- Streams-API: Kafka bietet eine Streams-API für die Erstellung von Stream-Verarbeitungsanwendungen. Mit dieser API können Entwickler robuste und skalierbare Echtzeitanwendungen erstellen, die Daten verarbeiten, während sie durch Kafka-Themen fließen.
- API verbinden: Kafka Connect ist eine API zur Erstellung von Konnektoren, die die Integration von Kafka mit externen Systemen erleichtern. Konnektoren ermöglichen es, Daten aus verschiedenen Quellen und Senken aufzunehmen oder zu exportieren.
Vorteile von Apache Kafka
- Publish-Subscribe-Nachrichtensystem: Mit Kafka senden Produzenten Nachrichten an Topics und Konsumenten abonnieren diese Topics, um sie zu empfangen. Dies ist als Publish-Subscribe-Paradigma bekannt.
- Verteilte Architektur: Kafka ist für den Betrieb als verteiltes System konzipiert, das horizontal über mehrere Knoten oder Server skaliert werden kann. Durch dieses verteilte Design werden hohe Verfügbarkeit und Fehlertoleranz gewährleistet.
- Fehlertoleranz: Kafka verteilt die Datenreplikation auf mehrere Broker oder Server, so dass die Daten im Falle eines Brokerausfalls auf anderen Knoten zugänglich bleiben.
- Skalierbarkeit: Der Cluster kann mit Kafka horizontal erweitert werden, indem weitere Broker hinzugefügt werden. Dadurch kann er steigende Datenmengen und Verarbeitungsanforderungen bewältigen.
- Dauerhaftigkeit: Kafka bietet eine dauerhafte Speicherung von Nachrichten, so dass sie auf der Festplatte erhalten bleiben. Aufgrund der Langlebigkeit bleiben die Nachrichten auch bei einem Ausfall eines Knotens erhalten.
- Hoher Durchsatz: Kafka ist für hohen Durchsatz optimiert und eignet sich daher für Szenarien mit einer großen Anzahl von Nachrichten pro Sekunde.
- Stream-Verarbeitung: Da die Stream-Verarbeitung von Kafka nativ unterstützt wird, können Entwickler Echtzeitanwendungen erstellen, die Daten verarbeiten und analysieren können, sobald sie im System ankommen.
Anwendungsfälle und Anwendungen
1. Finanzdienstleistungen
- Anwendungsfall: Transaktionsverarbeitung in Echtzeit
- Beschreibung: Finanzinstitute nutzen Apache Kafka zur Verarbeitung und Analyse von Transaktionsdaten in Echtzeit. Dabei geht es um die Überwachung von Aktiengeschäften, die Abwicklung von Finanztransaktionen und die schnelle Erkennung betrügerischer Aktivitäten.
- Anwendungsfall: Marktdaten-Feeds
- Beschreibung: Kafka wird für die Verarbeitung von Marktdaten-Feeds mit hohem Durchsatz verwendet und ermöglicht es Finanzorganisationen, Echtzeitdaten aus verschiedenen Quellen, einschließlich Börsen und Finanzmärkten, zu nutzen und zu analysieren.
2. Einzelhandel und E-Commerce
- Anwendungsfall: Inventarverwaltung
- Beschreibung: Einzelhändler nutzen Apache Kafka für die Bestandsverwaltung in Echtzeit. Ereignisse wie Produktverkäufe, Wiederaufstockung und Auftragsabwicklung werden gestreamt, um Lagerbestände effizient zu verwalten und datengesteuerte Entscheidungen zur Wiederaufstockung zu treffen.
- Anwendungsfall: Personalisiertes Marketing
- Beschreibung: E-Commerce-Plattformen nutzen Kafka, um Daten zum Nutzerverhalten in Echtzeit zu verarbeiten. Dadurch können sie nun maßgeschneiderte Vorschläge, gezielte Werbeaktionen und dynamische Preise anbieten, je nachdem, wie die Kunden mit ihnen in Kontakt treten.
3. Telekommunikation
- Anwendungsfall: Verarbeitung von Anrufdatensätzen (CDR)
- Beschreibung: Telekommunikationsunternehmen nutzen Apache Kafka für die Verarbeitung und Analyse von Anrufdatensätzen in Echtzeit. Dazu gehören die Verfolgung von Anrufmustern, die Überwachung der Netzwerkleistung und die Erkennung von Anomalien.
- Anwendungsfall: Ereignisgesteuerte Architekturen
- Beschreibung: Kafka wird für die Implementierung ereignisgesteuerter Architekturen in der Telekommunikation verwendet und ermöglicht die Echtzeitverarbeitung von Ereignissen wie Netzstörungen, Rechnungsaktualisierungen und Teilnehmeraktivitäten.
4. Gesundheitswesen
- Anwendungsfall: Überwachung der Patienten
- Beschreibung: Organisationen des Gesundheitswesens verwenden Kafka für die Patientenüberwachung in Echtzeit. Es ermöglicht das Streaming von Daten aus medizinischen Geräten, Überwachungssystemen und elektronischen Gesundheitsakten, um zeitnahe Warnmeldungen zu liefern und die Sicherheit der Patienten zu gewährleisten.
- Anwendungsfall: Datenintegration in Gesundheitssystemen
- Beschreibung: Kafka wird für die Datenintegration zwischen verschiedenen Gesundheitssystemen eingesetzt. Es erleichtert den Echtzeitaustausch von Informationen zwischen elektronischen Gesundheitsakten, Diagnosesystemen und anderen Anwendungen im Gesundheitswesen.
5. Logistik und Lieferkette
- Anwendungsfall: Sichtbarkeit der Lieferkette
- Beschreibung: Logistikunternehmen nutzen Kafka für die Echtzeitverfolgung von Sendungen und Beständen. Ereignisse wie Auftragserfüllung, Versandaktualisierungen und Bestandsänderungen werden gestreamt, um die Transparenz der Lieferkette zu verbessern.
- Anwendungsfall: Fuhrpark-Management
- Beschreibung: Kafka wird in Flottenmanagementsystemen eingesetzt, um Echtzeitdaten von Fahrzeugen zu verarbeiten und zu analysieren, um eine effiziente Routenoptimierung zu gewährleisten, das Fahrerverhalten zu überwachen und die Gesamtleistung der Flotte zu verbessern.
6. Medien und Unterhaltung
- Anwendungsfall: Streaming von Inhalten und Empfehlungen
- Beschreibung: Medien-Streaming-Plattformen verwenden Kafka, um Echtzeitdaten aus Benutzerinteraktionen zu verarbeiten. Es ermöglicht Inhaltsempfehlungen, personalisierte Wiedergabelisten und Echtzeit-Anpassungen der Streaming-Qualität.
- Anwendungsfall: Analytik der Nutzerbindung
- Beschreibung: Kafka wird für die Verfolgung der Benutzeraktivität in Medien- und Unterhaltungsanwendungen eingesetzt. Das Verständnis des Nutzerverhaltens, die Optimierung der Informationsverteilung und die Verbesserung des Nutzererlebnisses - all das profitiert von Echtzeit-Analysen.
7. Fertigung und IoT
- Anwendungsfall: Vorausschauende Wartung
- Beschreibung: Fertigungsunternehmen nutzen Kafka für die Echtzeitüberwachung von Industrieanlagen. Durch die Analyse von Sensordaten, die Erkennung von Anomalien und die Auslösung von Wartungswarnungen wird die vorausschauende Wartung erleichtert.
- Anwendungsfall: IoT-Datenerfassung und -verarbeitung
- Beschreibung: Kafka ist eine bevorzugte Wahl für die Verarbeitung großer Datenmengen von IoT-Geräten. Es ermöglicht die Aufnahme und Verarbeitung von Sensordaten in Echtzeit und erleichtert so Anwendungen wie intelligente Städte, intelligente Gebäude und industrielles IoT.
8. Spielen
- Anwendungsfall: Spielanalyse in Echtzeit
- Beschreibung: Online-Spielplattformen verwenden Kafka zur Verarbeitung von Echtzeit-Spielanalysen. Es ermöglicht die Verfolgung von Spielerinteraktionen und Spielereignissen und erleichtert die Bereitstellung von personalisierten Spielerlebnissen.
- Anwendungsfall: Event Sourcing in Gaming-Anwendungen
- Beschreibung: Kafka wird für Event-Sourcing in Spieleanwendungen eingesetzt, um Ereignisse im Spiel, Spieleraktionen und Änderungen des Spielstatus in Echtzeit aufzuzeichnen und zu verarbeiten.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass Apache Kafka eine vielseitige und leistungsstarke Lösung für Unternehmen darstellt, die die Komplexität der Echtzeit-Datenverarbeitung und ereignisgesteuerter Architekturen bewältigen wollen. Sein Open-Source-Charakter in Verbindung mit einer lebendigen Community sorgt für kontinuierliche Entwicklung und Innovation und macht Kafka zu einem Eckpfeiler in der Landschaft der verteilten Event-Streaming-Plattformen.







