Introduction
Les entreprises sont constamment à la recherche de méthodes permettant d'utiliser la puissance des données en temps réel pour obtenir des informations exploitables et prendre des décisions dans le monde en constante évolution de la technologie contemporaine. Apache Kafka est une technologie open-source de streaming d'événements distribués qui a révolutionné le traitement des données en temps réel. Dans cet article de blog, nous examinerons les capacités, la conception et les utilisations d'Apache Kafka et nous verrons pourquoi cette technologie est devenue un outil essentiel pour les entreprises qui s'attaquent aux difficultés associées à la gestion de quantités massives de données en continu.
Une initiative interne à LinkedIn a lancé le développement d'Apache Kafka, une plateforme open-source de streaming d'événements distribués, afin de répondre à l'évolution des besoins en matière de traitement des données en temps réel. Plus tard, après avoir réalisé le potentiel et l'importance de Kafka, LinkedIn l'a contribué à la Apache Software Foundation en la rendant open-source. Cette action a favorisé la coopération communautaire, ce qui a contribué à sa large acceptation et à son amélioration.
Énoncé du problème
La construction de systèmes évolutifs, distribués et tolérants aux pannes et la gestion de flux de données en temps réel posent plusieurs problèmes qu'Apache Kafka tente de résoudre. Dans l'environnement technologique actuel, qui évolue rapidement, les organisations doivent faire face à une augmentation considérable de la création de données provenant de diverses sources, notamment des appareils, des applications et des services. Les méthodes actuelles sont incapables de résoudre les nombreux problèmes posés par l'afflux de données en temps réel. Un système fiable, évolutif et tolérant aux pannes est crucial dans cette situation.
Qu'est-ce qu'Apache Kafka ?
De nombreux secteurs utilisent Apache Kafka de manière intensive pour la construction d'architectures basées sur les événements, l'agrégation de journaux, la surveillance et la diffusion de données en temps réel. Les organisations qui traitent des applications de données critiques à grande échelle le choisissent souvent en raison de sa tolérance aux pannes, de son évolutivité et de sa prise en charge du traitement des flux en temps réel.
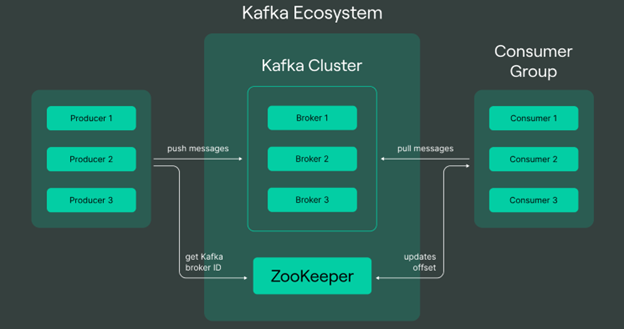
Voici quelques-unes des idées et des éléments principaux d'Apache Kafka :
- Sujets : Dans Kafka, les données sont organisées de manière logique en sujets, qui servent à acheminer les messages.
- Producteurs : La publication de déclarations sur des sujets liés à Kafka relève de la responsabilité des producteurs. Il peut s'agir de n'importe quel type de système ou d'application qui produit des données et les envoie au serveur Kafka pour qu'elles soient traitées.
- Les consommateurs : Les clients digèrent les messages postés sur les sujets auxquels ils sont abonnés. Lorsqu'il s'agit de tirer des conclusions ou d'agir sur la base de données en temps réel, ils sont essentiels.
- Courtiers : Kafka fonctionne dans une architecture distribuée où plusieurs serveurs, appelés courtiers, forment un cluster Kafka. Les courtiers veillent à répondre aux demandes des clients, à maintenir la tolérance aux pannes, ainsi qu'à stocker et à gérer les données.
- Partitions : Il existe des partitions pour chaque sujet, et un journal se trouve à l'intérieur de chaque partition. Kafka utilise des partitions pour répartir la charge entre plusieurs courtiers et consommateurs et traiter les messages en parallèle.
- Réplication : Kafka réplique les données entre plusieurs courtiers, ce qui garantit la tolérance aux pannes. Il y a un leader et plusieurs clones pour chaque division. La disponibilité des données peut être garantie en cas de défaillance d'un courtier en confiant la direction à l'une des copies.
- Zookeeper : Pour gérer la nature dispersée du cluster Kafka, Kafka utilise Apache ZooKeeper. L'élection des chefs des courtiers Kafka, leur configuration et leur synchronisation sont toutes gérées par le ZooKeeper.
- Compaction du journal : Kafka prend en charge le compactage des journaux, une fonctionnalité qui ne conserve que la dernière version de chaque enregistrement dans une partition. Cette fonctionnalité est particulièrement utile pour les scénarios dans lesquels vous souhaitez conserver une version compacte des données, comme la tenue d'un journal des modifications.
- API de flux : Kafka fournit l'API Streams pour la création d'applications de traitement des flux. Grâce à cette API, les développeurs peuvent créer des applications en temps réel robustes et évolutives qui traitent les données au fur et à mesure qu'elles transitent par les sujets Kafka.
- Connect API : Kafka Connect est une API permettant de créer des connecteurs qui facilitent l'intégration de Kafka avec des systèmes externes. Les connecteurs permettent d'ingérer ou d'exporter des données à partir de diverses sources et de divers puits.
Avantages d'Apache Kafka
- Système de messages par publication et abonnement : Avec Kafka, les producteurs publient des messages dans des rubriques et les consommateurs s'abonnent à ces rubriques pour les recevoir. C'est ce que l'on appelle un paradigme de publication et d'abonnement.
- Architecture distribuée : Kafka est conçu pour fonctionner comme un système distribué, ce qui lui permet de s'étendre horizontalement sur plusieurs nœuds ou serveurs. La haute disponibilité et la tolérance aux pannes sont assurées par cette conception distribuée.
- Tolérance aux pannes : Kafka répartit la réplication des données sur plusieurs courtiers, ou serveurs, de sorte que les données restent accessibles sur d'autres nœuds en cas de défaillance d'un courtier.
- Évolutivité : Le cluster peut être étendu horizontalement à l'aide de Kafka en ajoutant des courtiers supplémentaires. Cela lui permet de gérer des volumes de données et des demandes de traitement croissants.
- Durabilité : Kafka offre un stockage durable des messages, ce qui leur permet de persister sur le disque. Grâce à cette durabilité, les messages sont préservés même en cas de défaillance d'un nœud.
- Haut débit : Kafka est optimisé pour un débit élevé, ce qui le rend adapté aux scénarios avec un grand nombre de messages par seconde.
- Traitement des flux : Le traitement des flux étant pris en charge de manière native par Kafka, les développeurs peuvent créer des applications en temps réel capables de traiter et d'analyser les données au fur et à mesure qu'elles arrivent dans le système.
Cas d'utilisation et applications
1. Services financiers
- Cas d'utilisation : Traitement des transactions en temps réel
- Description : Les institutions financières utilisent Apache Kafka pour traiter et analyser des données transactionnelles en temps réel. Il s'agit de garder un œil sur les transactions boursières, de traiter les transactions financières et d'identifier rapidement les activités frauduleuses.
- Cas d'utilisation : Flux de données du marché
- Description : Kafka est utilisé pour traiter des flux de données de marché à haut débit, permettant aux organisations financières de consommer et d'analyser des données en temps réel provenant de diverses sources, y compris les bourses et les marchés financiers.
2. Commerce de détail et commerce électronique
- Cas d'utilisation : Gestion des stocks
- Description : Les détaillants utilisent Apache Kafka pour la gestion des stocks en temps réel. Les événements tels que les ventes de produits, le réapprovisionnement et le traitement des commandes sont diffusés en continu afin de gérer efficacement les niveaux de stock et de prendre des décisions de réapprovisionnement fondées sur des données.
- Cas d'utilisation : Marketing personnalisé
- Description : Les plateformes de commerce électronique utilisent Kafka pour traiter les données relatives au comportement des utilisateurs en temps réel. Elles peuvent désormais proposer des suggestions personnalisées, des promotions ciblées et des prix dynamiques en fonction de la manière dont les clients s'engagent avec elles.
3. Les télécommunications
- Cas d'utilisation : Traitement des enregistrements détaillés des appels (CDR)
- Description : Les entreprises de télécommunications utilisent Apache Kafka pour traiter et analyser les enregistrements détaillés des appels en temps réel. Il s'agit notamment de suivre les schémas d'appel, de surveiller les performances du réseau et de détecter les anomalies.
- Cas d'utilisation : Architectures pilotées par les événements
- Description : Kafka est utilisé pour mettre en œuvre des architectures pilotées par les événements dans les télécommunications, permettant le traitement en temps réel d'événements tels que les pannes de réseau, les mises à jour de la facturation et les activités des abonnés.
4. Santé
- Cas d'utilisation : Suivi des patients
- Description : Les organismes de santé utilisent Kafka pour le suivi des patients en temps réel. Il permet la diffusion en continu de données provenant d'appareils médicaux, de systèmes de surveillance et de dossiers médicaux électroniques afin de fournir des alertes en temps voulu et de garantir la sécurité des patients.
- Cas d'utilisation : Intégration des données dans les systèmes de santé
- Description : Kafka est utilisé pour l'intégration de données dans divers systèmes de soins de santé. Il facilite l'échange d'informations en temps réel entre les dossiers médicaux électroniques, les systèmes de diagnostic et d'autres applications de soins de santé.
5. Logistique et chaîne d'approvisionnement
- Cas d'utilisation : Visibilité de la chaîne d'approvisionnement
- Description : Les entreprises de logistique utilisent Kafka pour le suivi en temps réel des expéditions et des stocks. Les événements tels que l'exécution des commandes, les mises à jour des expéditions et les changements d'inventaire sont diffusés en continu pour améliorer la visibilité de la chaîne d'approvisionnement.
- Cas d'utilisation : Gestion du parc automobile
- Description : Kafka est utilisé dans les systèmes de gestion de flotte pour traiter et analyser les données en temps réel provenant des véhicules, ce qui permet d'optimiser les itinéraires, de surveiller le comportement des conducteurs et d'améliorer les performances globales de la flotte.
6. Médias et divertissements
- Cas d'utilisation : Diffusion de contenu en continu et recommandations
- Description : Les plateformes de diffusion multimédia en continu utilisent Kafka pour traiter les données en temps réel provenant des interactions avec les utilisateurs. Cela permet de recommander des contenus, de personnaliser les listes de lecture et d'ajuster en temps réel la qualité de la diffusion.
- Cas d'utilisation : Analyse de l'engagement des utilisateurs
- Description : Kafka est utilisé pour suivre l'engagement des utilisateurs dans les applications de médias et de divertissement. Comprendre le comportement de l'utilisateur, rationaliser la distribution de l'information et améliorer l'expérience de l'utilisateur, tout cela bénéficie de l'analyse en temps réel.
7. Fabrication et IdO
- Cas d'utilisation : Maintenance prédictive
- Description : Les entreprises manufacturières utilisent Kafka pour la surveillance en temps réel des équipements industriels. Grâce à l'analyse des données des capteurs, à la détection des anomalies et au déclenchement d'alertes de maintenance, il facilite la maintenance prédictive.
- Cas d'utilisation : Ingestion et traitement des données IoT
- Description : Kafka est un choix privilégié pour traiter de grands volumes de données provenant d'appareils IoT. Il permet l'ingestion et le traitement en temps réel des données de capteurs, facilitant ainsi les applications telles que les villes intelligentes, les bâtiments intelligents et l'IoT industriel.
8. Jeux
- Cas d'utilisation : Analyse des jeux en temps réel
- Description : Les plateformes de jeux en ligne utilisent Kafka pour traiter les analyses de jeux en temps réel. Cela permet de suivre les interactions des joueurs, les événements du jeu, et facilite la fourniture d'expériences de jeu personnalisées.
- Cas d'utilisation : Event Sourcing dans les applications de jeux
- Description : Kafka est utilisé pour l'approvisionnement en événements dans les applications de jeu, l'enregistrement et le traitement des événements dans le jeu, les actions des joueurs et les changements d'état du jeu en temps réel.
Conclusion
En conclusion, Apache Kafka représente une solution polyvalente et puissante pour les organisations qui cherchent à naviguer dans les complexités du traitement des données en temps réel et des architectures pilotées par les événements. Sa nature open-source, associée à une communauté dynamique, garantit un développement et une innovation continus, faisant de Kafka une pierre angulaire dans le paysage des plateformes de streaming d'événements distribués.







