典型的なディープラーニングモデル開発パイプラインには、データの取得、データの準備、モデルのトレーニング、モデルの性能ベンチマーク、モデルの最適化、そして最後にターゲットデバイスへのモデルのデプロイが含まれる。ディープラーニング・モデルはデータから直接表現を学習するため、データが多ければ多いほど性能が向上すると言える。
すべてのバリエーションを含む、このような膨大な量のデータを手作業でキャプチャするのは面倒な作業だ。さらに、このような膨大な量のデータに注釈を付けるのは、これまた非常に時間と労力がかかる。この問題を解決するために、Nvidiaは、ML(機械学習)エンジニアが簡単に大量の注釈付きデータセットを作成できるシミュレータ(Isaac Simulator)を開発しました。
アイザック・シミュレータから画像データセットを取り込むために、Blenderツールで作成したシーンをインポートする。シーンと他の必要なオブジェクトのモデルファイルをシミュレータにインポートした後、テクスチャやライティングなど、様々な領域のランダム化を適用して、データセットに実世界のバリエーションを組み込むことができます。生成されたデータセットは、Nvidiaが提供するTAOツールキットの助けを借りて、DLモデルの学習に使用される。TAOツールキットは、モデルのトレーニング、拡張、最適化のためのワンストップ・ソリューションである。TAOツールキットを使ってトレーニングしたモデルは、TensorRTやTriton実行サーバで実行可能な.trtや.plan形式でエクスポートできます。このブログでは、これらのツールの詳細と、ディープラーニングモデルのトレーニングとデプロイメントにどのように活用できるかを見ていきます。
我々はBlenderとIsaacシミュレータを使って合成トレーニングデータセットを作成した。Blenderはフリーでオープンソースの3D作成スイートで、モデリング、リギング、アニメーション、シミュレーション、レンダリングなど、3Dパイプライン全体をサポートしている。Blenderで作成されたシーンは、Isaacシミュレータにインポートされます。NVIDIA Isaac Sim™は、スケーラブルなロボットシミュレーション・アプリケーションであり、ドメインランダム化、グランドトゥルース・ラベリング、セグメンテーション、バウンディングボックスなどの合成データ生成のための広範なツールを提供する合成データ生成ツールです。
Isaac simを使った合成データ生成の詳細については、以下のブログをご参照ください:コンセプトから完成まで:Nvidia Isaac SimとBlenderによるロボティクス向け3Dシーン作成の効率化
AMRのような非線形システムを扱う場合、カルマンフィルタアルゴリズムにいくつかの変更を加える必要があります。各予測および更新ステップの後も、状態表現がガウス分布のままであることを保証するためには、運動モデルと測定モデルを線形化する必要があります。これは、テイラー級数を用いて非線形モデルを線形モデルとして近似することで行われます。このように拡張されたカルマンフィルタは、拡張カルマンフィルタと呼ばれます。
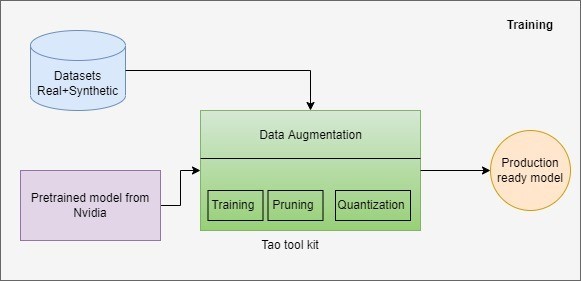
Nvidiaは、TAOツールキットと呼ばれる、開発者や企業がモデルのトレーニングと最適化プロセスを加速できるローコード・ソリューションを提供している。TAOツールキットは、AIモデルやディープラーニングフレームワークの複雑さを抽象化することで、初心者を支援します。NVIDIA TAOツールキットを使えば、転移学習の力を利用し、NVIDIAの事前学習済みモデルを独自のデータで微調整し、推論のためにモデルを最適化することができます。
TAOツールキットは、物体検出、画像分類、セグメンテーション、および会話AIのための多数のコンピュータビジョン事前学習済みモデルを提供します。TAOツールキットで生成されたモデルは、TensorRTと完全に互換性があり、TensorRT用に高速化されています。
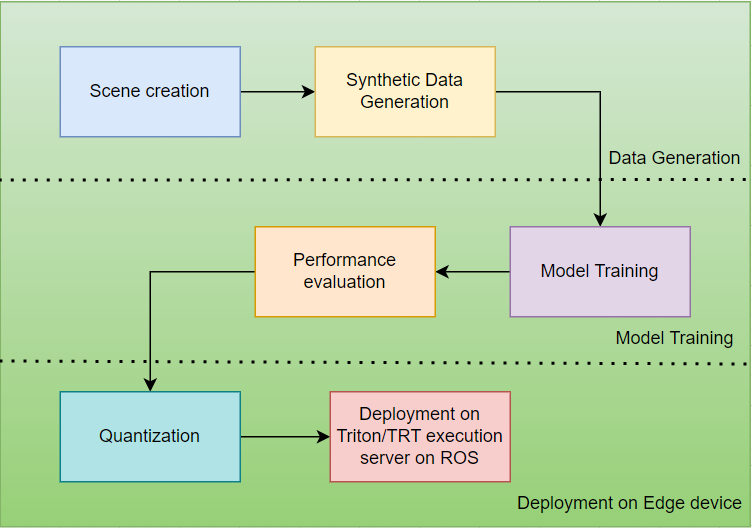
我々のトレーニングパイプラインは、効率的かつ迅速にモデルを開発するためにNvidia TAOツールキットを利用している。合成データ生成から展開までのワークフローを以下に示す:
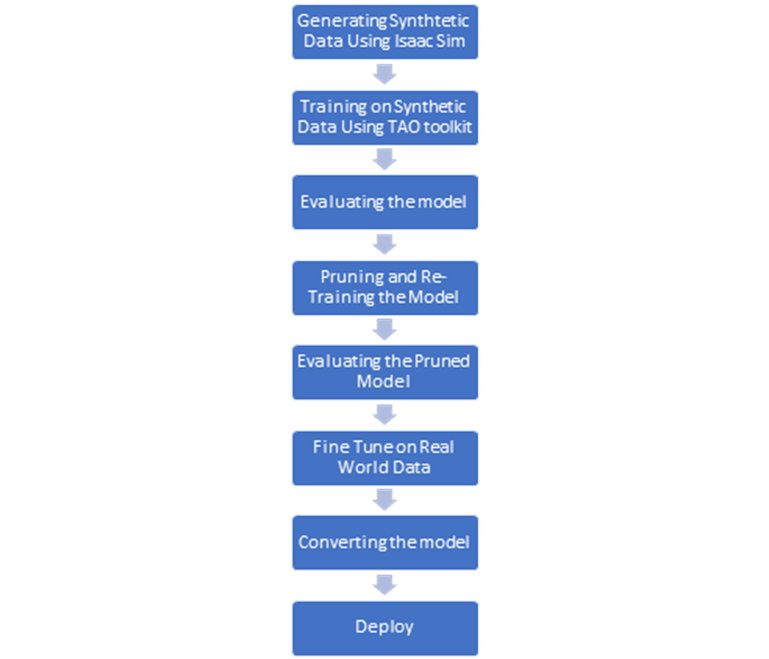
TAOツールキットを使用してモデルをトレーニングする際、TAOパイプライン全体で使用されるすべてのリソース/アセットがTAO Dockerコンテナにマウントされ、そこから使用されることに注意することが重要です。トレーニング中は、システムディレクトリのパス(ソース)とTAO Dockerコンテナのパス(デスティネーション)の両方に環境変数が作成されます。mount.json」ファイルには、ソースとデスティネーションのパスが含まれています。
トレーニング中は、最後まですべての仕様ファイルで同じ次元を維持することが重要です。途中で次元を変えると、出力メトリクス(Precision、Recall、MIOU)が間違ってしまい、モデルのパフォーマンスが低下します。
物体検出タスクにはDetectNetV2を選択し、アイザック・シミュレータから生成された合成データで微調整を行った。学習されたモデルファイルはエクスポートされ、推論のためにハードウェア上に配置される。学習パイプラインのブロック図を以下に示す:
Gazeboは、ROS 2に対応したシミュレーション環境であり、ロボットシステムのテストに高い柔軟性を提供します。この環境では、センサーノイズを加えたり、さまざまな摩擦係数を試したり、車輪エンコーダの精度を下げたりすることが可能であり、これにより、実世界においてAMRの状態推定に影響を与えるような現実的なシナリオを再現することができます。
センサーフュージョンの性能を定量的に評価するために、ループ閉鎖テストを実施することができます。これは、AMRの初期位置と最終位置が同じになるように、ランダムに閉じた軌跡上でAMRを走行させるテストです。 その後、IMUと車輪エンコーダを融合させたEKFによる状態推定結果をプロットし、生データである車輪エンコーダのみを用いた状態推定結果と比較することができる。理想的には、AMRの状態推定値として、x、y、ヨー角がそれぞれ(0, 0, 0)となることを目指す。
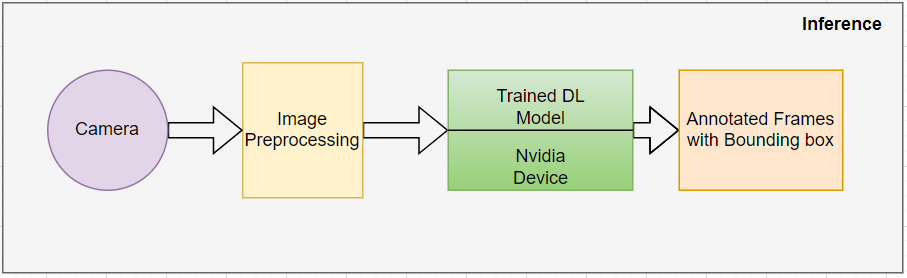
モデルが所望の精度を達成し、すべての性能チェックに合格すると、.trtまたは.planファイルにエクスポートされます。エクスポートされたモデルは、リアルタイム推論のためにNvidiaのエッジデバイス上に配置することができます。推論パイプラインは、カメラから送られてくるRGB画像をリアルタイムで受け取り、画像に必要な前処理を施してモデルの入力サイズに適合させ、望ましいパフォーマンス/スループットを達成します。以下のブロック図は推論フローを表しています:
このブログでは、合成データ上でDLモデルを素早く訓練し、リアルタイムの推論に展開する方法を見た。合成データで段ボール箱検出のモデルを訓練し、実世界で90%以上の精度を達成しました。将来的には、合成データと実世界のデータを混ぜて実験し、それがモデルの全体的な性能にどのような影響を与えるか見てみたい。


信号処理、画像処理、コンピュータビジョン、ディープラーニング、機械学習などの分野で4年以上の経験を持つ。 信号処理の修士号を取得し、現在は人工知能の博士号を取得中。

ハイデラバード大学で人工知能の修士号を取得。現在、eInfochips Inc.でソリューションエンジニアとして勤務。専門はニューラルネットワーク、ディープラーニング、コンピュータビジョンアルゴリズム。
当社の自動車ソリューションの専門家による30分間の相談会をご予約ください
当社のバッテリー管理ソリューションの専門家による30分間の相談会をご予約ください
当社の産業・エネルギーソリューションの専門家による30分間の相談会をご予約ください
当社の専門家による30分間の相談を予約する
